Embedded Open Source Summit (EOSS) is an umbrella event for open source embedded projects and developer communities to come together under one roof for important collaboration, discussions and education. The event is composed of different micro conferences including Embedded Linux Conference, Zephyr Developer Summit, and Safety-Critical Software Summit.
The Safety-Critical Software Summit took place under the Embedded Open Source Summit, where more than 860 individuals attended in-person at the event with 79% holding technical positions.
This presentation uses practical examples to teach developers how to think about software in a safety critical context. It identifies the limitations of safety engineering and give developers a conceptual foundation for working within those constraints. At the heart of these limitations is the introduction of the “Cinderblock Problem.” Chuck uses this problem as a proposed shorthand for expressing the limitations of safety engineering in the context of software design and development.
This is an abstract of a blog “Safety Frontier: A Retrospective on ELISA” originally published on Codethink by Paul Albertella. ELISA (Enabling Linux In Safety Applications) is an open source project that brings together functional safety practitioners, software engineers, and open source software contributors. The project aims to tackle the substantial challenge of integrating Linux into safety-critical systems, which include applications such as those found in vehicles, medical devices, and even aircraft, traditionally relying on bespoke software developed with rigorous controls.
As technologies in these areas evolve, there’s a growing inclination to utilize general-purpose and open source software. ELISA confronts the complexities of Linux, which consists of nearly 30 million lines of code, to establish methodologies that ensure its safe application. This involves creating safety arguments and conducting detailed safety cases backed by robust engineering and quality management processes.
Paul reflects on the collaborative journey of ELISA, emphasizing its community-driven approach. He discusses the difficulty in using a general-purpose OS like Linux in safety-critical environments, where each application requires specific adaptations and rigorous testing. The blog also touches on the ongoing initiatives within ELISA to outline essential Linux components for safe usage and to identify its limitations and risks.
The most recent ELISA workshop in Lund, Sweden, serves as a testament to the project’s vibrant collaboration and shared expertise, addressing the continuous challenges of integrating advanced software systems safely. Albertella’s narrative captures the essence of ELISA’s mission to not just adapt Linux for safe use but to foster a safety culture that benefits from and contributes to the open source community.
This abstract captures the essence of the themes explored in the original blog, making it an essential read for those involved in software engineering, safety standards, or open source projects interested in the intersection of open source software and functional safety. For more detailed information, you can read the original content on the Codethink blog.
Embedded Open Source Summit (EOSS) is an umbrella event for open source embedded projects and developer communities to come together under one roof for important collaboration, discussions and education. The event is composed of different micro conferences including Embedded Linux Conference, Zephyr Developer Summit, and Safety-Critical Software Summit.
The Safety-Critical Software Summit took place under the Embedded Open Source Summit, where more than 860 individuals attended in-person at the event with 79% holding technical positions.
At the Safety Summit, Philipp Ahmann, ETAS presented on the ELISA Project, which focuses on enabling open source software in safety-critical applications. The growing need for safety integrity standards in open source projects offers both challenges and opportunities to enhance software quality, particularly in testing, documentation, robustness, and dependability. ELISA aims to be a central hub for safety-critical workloads, collaborating with projects such as Xen, Zephyr, Yocto, and SPDX.
Philipp’s session began with an overview of ELISA’s goals and activities. The focus then shifted to an open discussion on elements, processes, and tools that can enhance trust in open source software for safety, paving the way towards potential certification. The session emphasized the importance of community involvement and collaboration to address the challenges and opportunities in making open source software safety-certifiable.
Key points of the presentation included the focus on various open source projects and their relationship to functional safety. For instance, the Zephyr project integrates safety from the design phase, with premium members having access to comprehensive safety documentation and testing materials. In contrast, Xen prioritizes security and industrial-grade operations, offering rigorous quality processes and strong traceability from initial commit to testing pipelines. Philipp emphasized the importance of community involvement, noting that premium members, like AMD, drive the safety certification efforts for Xen.
The ELISA project distinguishes itself by not directly delivering a “safe Linux,” but by supporting integrators and system creators in making Linux-based systems safety-certifiable. Key members include Red Hat, SUSE, Canonical, Wind River, and Elektrobit, among others. ELISA focuses on creating reproducible systems with CI pipelines that cover documentation, testing, and error detection, enabling users to hook into various stages of the process.
Philipp also discussed the complexity of certifying Linux-based systems due to their inherent flexibility and configurability. He highlighted the challenges of aligning Linux with traditional safety-critical operating systems, which are typically small, fixed, and non-configurable. The presentation also covered the broader scope of ELISA’s work, which includes interactions with various standards bodies and the development of reference systems to demonstrate safety applications.
The ELISA project promotes best practices and aims to ensure that its work is accepted by the open source community. This includes contributions to the Linux kernel and related projects, as well as interactions with other initiatives like CIP and SOAFEE. He also mentioned ongoing efforts to develop use cases and practical applications, such as electric vehicle charging stations and medical devices, to better understand and address the safety needs of different industries.
In conclusion, the ELISA Project is committed to enabling the use of open source software in safety-critical applications through collaboration, comprehensive documentation, robust testing, and continuous improvement. The project seeks to engage the broader community in its efforts, recognizing that the collective expertise and contributions of its members are essential to achieving its goals. The presentation underscored the importance of open communication, shared best practices, and a commitment to safety in driving the project forward.
Embedded Open Source Summit (EOSS) is an umbrella event for open source embedded projects and developer communities to come together under one roof for important collaboration, discussions and education. The event is composed of different micro conferences including Embedded Linux Conference, Zephyr Developer Summit, and Safety-Critical Software Summit.
The Safety-Critical Software Summit took place under the Embedded Open Source Summit, where more than 860 individuals attended in-person at the event with 79% holding technical positions.
At the Safety Critical Software Summit, Stefano Stabellini, AMD provided a comprehensive update on the Xen Project’s advancements toward achieving safety certification. The Xen Project is an open source, static partitioning hypervisor designed for embedded and automotive applications. It ensures strict isolation between domains, making it a prime candidate for the highest levels of safety certification, such as ISO 26262 for automotive and IEC 61508 for industrial applications.
Stefano detailed the collaborative efforts between AMD and the Xen Community, initiated in 2023, to make Xen safety-certifiable across AMD x86 and ARM architectures. Over nine months, the team has integrated 80% of the relevant MISRA C rules into Xen’s coding standards and resolved numerous MISRA C violations. The introduction of MISRA C checkers into the upstream Xen CI loop has been a critical step in maintaining code quality by preventing new violations from entering the codebase.
The talk emphasized the Xen Project’s rigorous approach to safety certification, highlighting the adoption of a flexible and adaptable MISRA C compliance strategy. This approach included deviating certain MISRA rules that were too restrictive or not entirely applicable to Xen’s mature codebase, while still leveraging MISRA’s robust guidelines to improve code safety and quality.
Stefano also discussed the development of software safety requirements, a key component of the certification process. These requirements are structured hierarchically into market requirements, product requirements, and detailed software safety requirements, each linking to specific tests and traceable through tools like OpenPASS Trace.
The presentation emphasized the importance of integrating MISRA C scanning into the continuous integration (CI) process to detect and address violations early. Additionally, it highlighted the need for using modern tools and methodologies for writing and managing safety requirements, aligning them with open-source community practices.
Stefano concluded by outlining the next steps, including the ongoing upstreaming of safety requirements and further development of the testing infrastructure.
Written by Kate Stewart, Vice President of Dependable Embedded Systems at the Linux Foundation, and Philipp Ahmann, Senior OSS Community Manager at ETAS and Chair of the ELISA Project Technical Steering Committee
Overview
In Lund, Sweden, Volvo recently hosted the ELISA workshop, aligning with their strong commitment to improving safety. The event was a perfect match for the ELISA community, attracting a full capacity of 30 in-person attendees and engaging over 15 virtual participants. The workshop not only provided valuable discussions and brainstorming sessions but also offered attendees a taste of Swedish hospitality with delightful breaks and lunches – facilitating a lively “hallway track”. The lively conversations sometimes made it challenging to stick to the schedule, but the energetic atmosphere fostered productive exchanges of ideas.
Insightful sessions extract
Presentation: Constant Flow of Increasing Challenges for a Safety Manager
With Håkan Sivenkrona we had an inspiring presentation from our hosting company Volvo, which also will lead into a follow up seminar dedicated to Safety Elements out of Context (SEooC). In today’s dynamic environment, standards are constantly evolving. It is crucial for both proprietary and open systems to adapt to this shifting landscape and embrace continuous safety compliance. As a community, we must come together to explore ways to consistently deliver a Safety Case in the future. Safety systems need to be ready for the usage of open source developed software and open source software need to be enabled to fulfill the demands of various directives, security and safety standards. Public expectations and established best practices will further drive safety innovation.
Presentation: SPDX safety profile and implications on code and traceability
During this session, we discussed the important factors that need to be considered and integrated into the Safety Cases moving forward. We also explored the efforts of the System Package Data Exchange project in capturing metadata to enhance this process. In addition to the Linux kernel and user space software, it is crucial to understand the origin of datasets, model training, and services for effective safety analysis in the future. By automating the generation of this information, we can ensure better traceability of requirements when there are changes in the inputs to the Safety Cases.
Presentation: safety mechanisms to be considered to meet ASIL levels in Automotive
Naresh Ravuri from Magna, provided an excellent overview of the work that they’ve been doing to tackle the top level safety goals from OEM perspective. They emphasized the importance of identifying a critical path even when all requirements are derived. The decomposition of the use case plays a crucial role in ensuring that if one part fails to perform a task, another part can take over. It is essential to have a deep understanding of the Linux system to avoid incorrect system decomposition. Additionally, considering the data-driven path is vital for conducting a thorough analysis. Lastly, it is important not to overlook the impact of the build (compiler) and runtime environments (libraries) on the overall system.
Presentation: ELISA in the world of Software Defined Vehicles
Almost the whole Automotive Industry is currently looking into software defined vehicles with high performance computers (HPCs). During the ELISA workshop the participants discussed this from a practical point of view and what it means to “let it crash”. Coming from Cloud Native it was presented how to plan for potential system failures and how to recover from that. The architectural assumptions are important and how a system is tailored and methods for splitting critical resources from less critical system parts. The presentation was brought to the community by EMQ who are serving multiple automotive customers with MQTT solutions.
Discussion: core parts of the kernel – initial focus on the “TINY” configuration
During the workshop, the approach of starting with the “TINY” config and gradually adding or removing components was discussed. By clearly defining the core set of the linux kernel, it becomes easier to prioritize important aspects which are crucial for the safety argumentation of the kernel. While initially it was considered to avoid hardware and architecture specific code, this may not be feasible. By extending the “TINY” configuration with other components, not only does it enhance the system, but it also demonstrates a methodology for improving the overall functionality of the kernel.
The follow up of the initial discussion on “TINY” will be split across various working groups inside ELISA. The Linux Features working group is already exploring suitable reference hardware like an ARM 64 bit QEMU. The Architecture Working Group will start the analysis based on their input. The build and booting of the reference hardware integrated into a CI is subject to the Systems WG.
Discussion: state of available tooling
The tooling for analyzing the Linux kernel is constantly improving. While there are already several tools integrated into the kernel, we are also exploring the inclusion of additional analysis tools that have shown their usefulness. If you’re interested in understanding call graphs, you can check out the ks-nav tool work available at: https://github.com/elisa-tech/ks-nav
Why ks-nav is important can be extracted also from the slides and get some workshop feeling by clicking on the embedded YouTube links: State of ks-nav.pdf
Summary of workshop and main takeaways
The good mixture of participants continue to bring new ideas into the discussion when meeting in person. In particular the pointing to use of the TINY Linux configuration for the core was brought in by a first time Linaro representative. It is always important to widen the spectrum.
While there is still a long way to go until we have proven processes for enabling Linux in Safety Applications, there are starting to emerge some excellent ideas and as we refine them, we should be able to formalize them. It’s very easy for folks to make destructive statements, but we’re seeing that the open dialog can be turned into a more positive outlook, as illustrated by the engineering approach for safe systems with linux, where discussion landed on defining a design element and building up from there.
It is important to remember that a closed source OS may be as vulnerable as Linux in working with an open source ecosystem. However in Linux we have an open system and can actually see how it operates. Maybe in other closed OS and in company development the same issues show up, but nobody knows about it, as there is no expert and possibility to analyze.
The automotive industry is increasingly interested in utilizing Linux for high-performance computers in vehicles. The complexity of the software-defined vehicle, centralized compute units, and complex system architectures pose challenges for traditional product development using closed-source proprietary real-time operating systems (RTOS). Linux, on the other hand, is capable of meeting these demands, which is why its adoption in the automotive industry is expected to continue to grow, but they still need the path of safety argumentation and certification.
Interesting enough even with slightly different motivation also Aerospace observes wider usage of high performance computers and at same time a wider usage of Linux demanding safety certification. Maybe the next workshop will be hosted in the wider (aero-)space ecosystem to serve the other vertical branch in ELISA more. So, stay tuned for when and where our next Workshop will be.
Still, a lot of work is needed to have a safety argumentation for Linux, but we are making progress.
Thanks to hosts
We would like to express our gratitude to Volvo Cars, especially Robert F, for organizing the venue and hosting us. We also appreciate the walking tour of Lund, the delicious meals, and the fascinating tour of MAX IV (https://www.maxiv.lu.se/). During the tour, the MAX IV team showcased their research using beamlines and accelerators. We learned that Linux is widely used as the IT infrastructure throughout the research site, although it is not considered safety-critical. These examples further demonstrate the trust and widespread adoption of Linux.
As hallway and networking is important when meeting face to face, Volvo arranged a great dinner for the participants where a lot of topics from MAX IV, as well as “the digital safety belt” and the directions of the ISO26262 were discussed and which role Linux plays in all of this. Like Volvo has released their patent on the safety belt for the sake of saving people’s life over making money with a patent many years back, let us hope that the same will happen to software in vehicles and make open source software like Linux the next “digital safety belt”.
Contribute
If any of these topic areas is of interest to you, please feel free to sign up for the mailing lists at https://lists.elisa.tech; show up at one of the working group meetings; and contribute to the discussion.
Stress-ng has a proven track record for stress testing Linux systems and forcing out system bugs. As past of the ELISA Seminar series, Colin King, Principal Engineer at Intel, gave a presentation titled, “Improved System Stressing with stress-ng.” His talk describes new stress-ng features and the future roadmap for stress-ng.
<!– wp:paragraph –>
The ELISA Seminar Series focuses on hot topics related to ELISA’s mission to define and maintain a common set of elements, processes and tools that can be incorporated into Linux-based, safety-critical systems amenable to safety certification. Speakers are members, contributors and thought leaders from the ELISA Project and surrounding communities. Each seminar comprises a 45-minute presentation and a 15-minute Q&A, and it’s free to attend. You can watch all videos on the ELISA Project Youtube Channel ELISA Seminar Series Playlist here.
The Open Source Summit Europe, which takes place on September 16-18 in Vienna, Austria, is packed with technical content. It is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem.
As a conference umbrella, Open Source Summit is composed of a collection of events covering the most important technologies, topics, and issues affecting open source today. The Critical Software Summit is one of those microconferences.
As open source is found more and more in safety-critical products and infrastructure, the need to ensure dependability and reliability has increased. This event gathers developers focused on solving these issues, to figure out how we can increase the confidence of using OS projects in safety, mission, and business-critical applications.
Several of ambassadors, contributors and leaders from the ELISA Project will be giving presentations on Monday, including:
Creating and maintaining a safety critical project comes with a lot of challenges. A central issue is keeping your documentation, starting from planning and guideline documents, down to requirements, safety analysis, reviews and tests, consistent and up to date. These artefacts often have their own lifecycle and are natively managed in different tools, with usually great traceability capabilities regarding dependencies between these artefacts as long as you stay within one tool or within a (usually propriety) tool family of one single tool vendor. Currently the resulting traceability gaps between these tools are handled either by the popular engineering tools like MS Excel or methods like “search for identical names”, depending highly on manual maintenance.
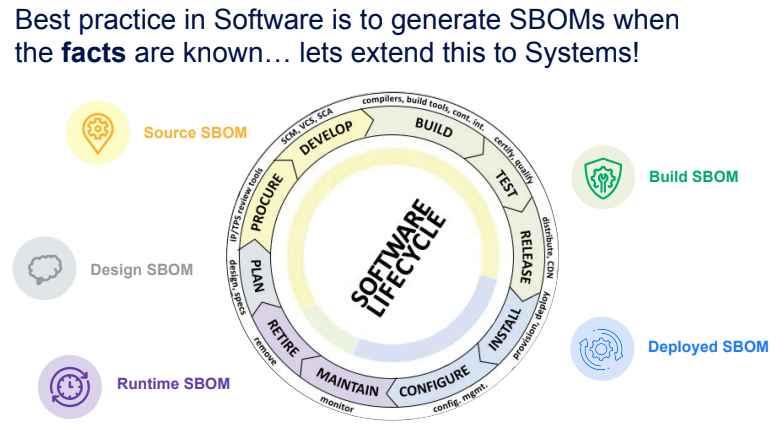
Using SPDX relationships, the upcoming Safety Profile in SPDX 3.1 will provide a model to represent all these dependencies as a knowledge model that can be used both to analyse possible impacts after a change (be it because of a security update or functional variants of your product), provide evidence of completeness and compliance as a Safety SBOM or simply keep track of your product variants.
In Safety Critical applications it is mandatory to ensure Sw Requirements traceability to Sw Specifications, Test Cases, Test Results, Bugs and more. The process leading to this goal is usually complex and time-consuming and it is essential to understand the state step by step and highlight what remains to be done. Moreover, for the intrinsic nature of a software project, we need to ensure traceability and test verification following any evolution in the ecosystem of the project.
BASIL The FuSa Spice, is an open source sw that provides a quality management solution aimed to address the above mentioned challenges for SW developments that are code driven and equally for the ones requirements driven.
We will see how to implement in BASIL Sw Requirements traceability to the source Code and to existing upstream Test Cases, how to execute them, how to navigate Test Results and artifacts and how to link failures to a bug in a bug tracking system.
We will also go into the details of a pipeline implementation based on the BASIL HTTP Api to understand how changes in one or more work items can be managed through automation with the goal of implementing a continuous certification framework.
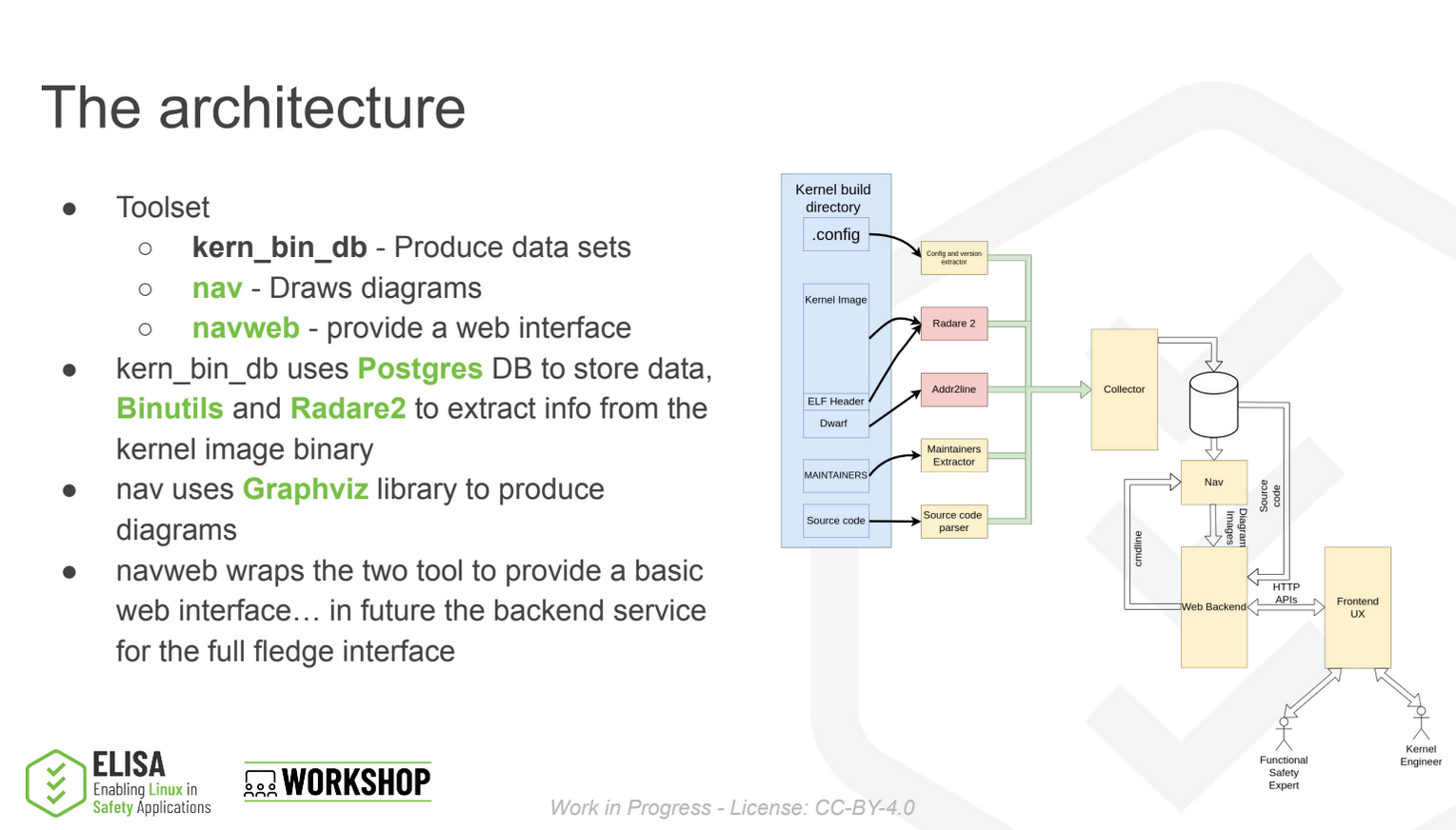
In order to make functional safety claims on SW components, having a clear understanding of the underlying software architecture is crucial. However, if SW architectural documentation is missing, understanding how software operates and how its parts fit together can be challenging. For the Linux kernel and many other OSS SW, such documents are absent and instead, analysts must rely on code, which can be hard to read. ks-nav is a tool designed to help in reverse engineering and understanding the code by generating diagrams that highlight the interactions between code elements and sub-elements.
ks-nav relies on binary images instead of source code analysis to get rid of the uncertainty introduced by configurations, compiler optimizations, and any other toolchain related issues. Additionally, using the MAINTAINERS file, it precisely pinpoints subsystems, enabling users to delve into their interactions with clarity.
This session focuses on: * Why understanding the code is critical in FuSa activities; * How ks-nav works, how it addresses the various challenges of analyzing the code; * An example of how ks-nav can be used to support an expert-driven FMEA for a specific use case.
The increasing computation power of embedded CPUs has revolutionized industries such as Automotive, Aerospace, or Industrial by enabling centralized and enhanced use cases, software-defined functionalities, and increased automation. The challenges of this increased complexity are often addressed by incorporating Open Source Software, particularly Linux, virtualization and RTOS. As these industries are heavily regulated by quality and safety-integrity standards, the certification of these highly complex systems becomes crucial.
Starting from the similarities and overlaps in system architecture design across use cases, this talk will explore the demands imposed by safety integrity standards in various industries. To develop these systems and adhere to required processes, the integration of tools and a high degree of automation is essential.
The authors show how Open Source projects bridge the gap between open source and safety-criticality, introducing tools and processes, and showcasing collaborative efforts in creating reproducible example system architectures. These systems can serve as a foundation for companies and projects adopting Open Source in safety-critical applications.
The full schedule for the Critical Software Summit Schedule can be viewed here. Register here to attend in-person. Virtual registration is not required to access the event live stream. All conference sessions will be live-streamed to the Linux Foundation YouTube channel with freely available access during the event. Live stream links for each session can be accessed from each session listing in the schedule. More information is coming soon.
Stay tuned by subscribing to the ELISA Project newsletter or connect with us on Twitter, LinkedIn or mailing lists to talk with community and TSC members.
Free and open-source software (FOSS), particularly Linux, is gaining traction in automotive embedded solutions and High-Performance Computing Platforms due to its advantages over proprietary alternatives. However, assuming liability for FOSS-based issues presents challenges in software quality assurance and risk control. The automotive industry, relying on the ASPICE maturity model and safety standards for assessment, faces a mismatch with the decentralized nature of FOSS development, driven by community contributions. FOSS’s decentralized quality assurance measures make single-entity regulation impractical, compounded by the extensive Linux code base, rendering low-level ASPICE Process Reference Model processes economically infeasible.
This presentation proposes a tailored approach incorporating ASPICE with compensation measures for FOSS specifics. This aims to achieve quality assurance and risk mitigation goals, enabling assessment through the ASPICE Process Assessment Model and adherence to functional safety standards. The video details these strategies, emphasizing a nuanced approach harmonizing FOSS principles with industry standards for reliability and safety in automotive computing. Watch here:
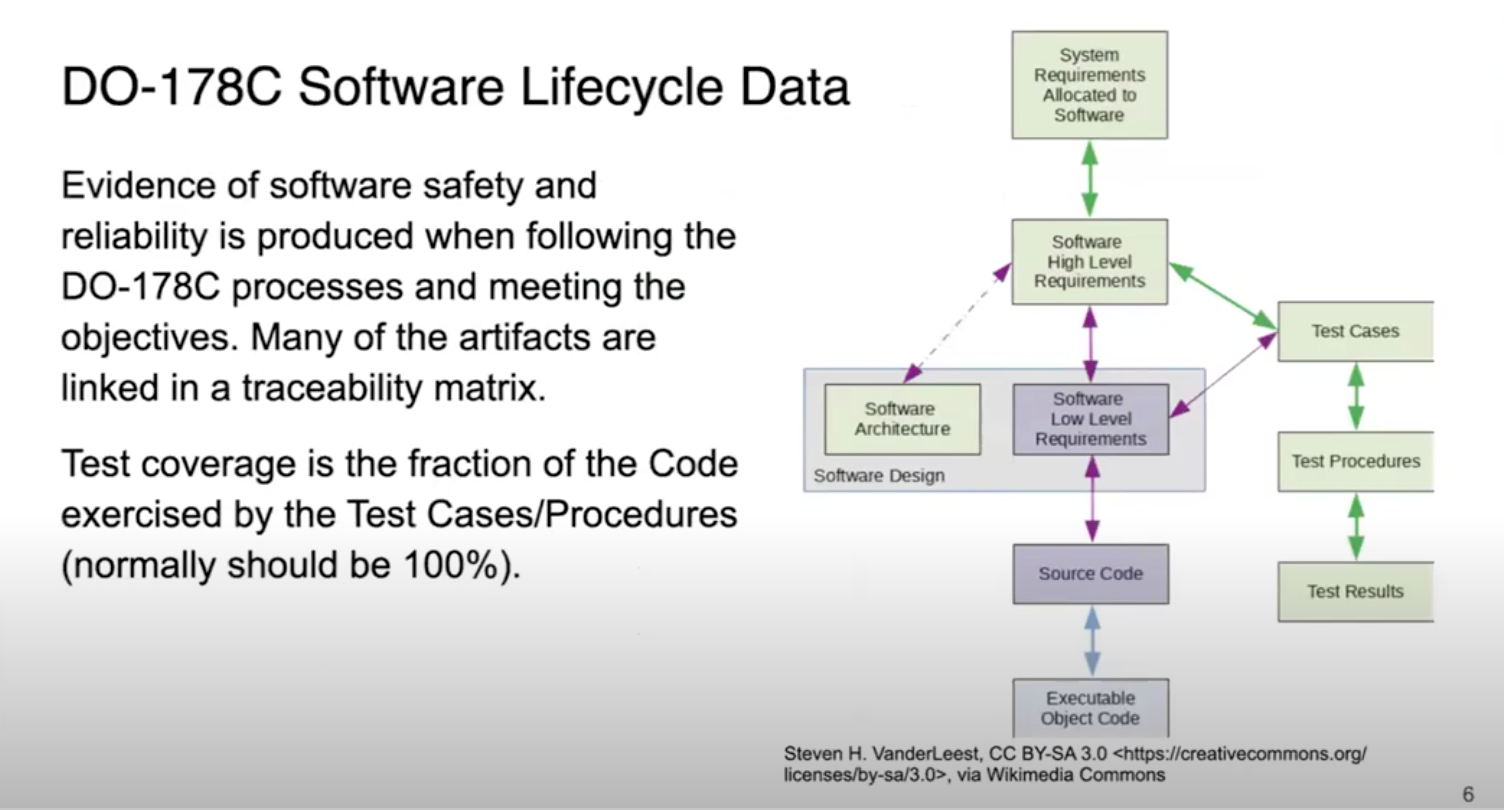
Although the Linux operating system has been used widely in many industries, adoption in aerospace has been slow due to the rigorous assurance evidence required as part of flight certification. The guidance for commercial flight software in most of the world is RTCA DO-178C, which identifies five progressively more rigorous levels of assurance. Providing the software life cycle data outlined by DO-178C is a daunting task for software as large and complex as Linux. In this project we focus on three objectives from DO-178C related to code coverage — the fraction of the source code that is exercised by testing. The three types of code coverage in DO-178C are statement coverage, decision coverage, and Modified Condition/Decision Coverage (MC/DC). The last of these, MC/DC, is only required for Software Level A, the highest level of assurance.
For operating system kernels like Linux, measuring code coverage is challenging because of the unique execution environment compared to user space. Measuring MC/DC is even harder given the intricacy of the metric and limitations of tools. We share our experience in measuring Linux kernel’s code coverage, with an emphasis on MC/DC. We describe how we have enabled measuring Linux kernel’s MC/DC for the first time, by enhancing both the toolchain and the kernel itself. We also discuss the generalizability of our approach across different kernel versions and opportunities for improving coverage with kernel testing suites like KUnit and kselftest.
The ELISA Seminar Series focuses on hot topics related to ELISA’s mission to define and maintain a common set of elements, processes and tools that can be incorporated into Linux-based, safety-critical systems amenable to safety certification. Speakers are members, contributors and thought leaders from the ELISA Project and surrounding communities. Each seminar comprises a 45-minute presentation and a 15-minute Q&A, and it’s free to attend. You can watch all videos on the ELISA Project Youtube Channel ELISA Seminar Series Playlist here.
Ferrocene is a fully open source toolchain to enable the use of the Rust programming language in safety-critical environments. It is a proper downstream of the main Rust compiler – rustc. This includes all documentation.
The mission of Ferrocene is to bring open source practices to safety-critical industries and improve the Rust open source ecosystem through safety-critical practices.
Ferrocene is also fully qualified using only open source tooling.
But what does that mean in practice? In this talk, I’ll walk you through our findings when qualifying the Ferrocene compiler toolchain using fully open source tools. A particular eye will be on the conditions that enabled the Ferrocene project to build a feedback loop with the Rust project and how they may inform your approach towards other FOSS projects.
The ELISA Seminar Series focuses on hot topics related to ELISA’s mission to define and maintain a common set of elements, processes and tools that can be incorporated into Linux-based, safety-critical systems amenable to safety certification. Speakers are members, contributors and thought leaders from the ELISA Project and surrounding communities. Each seminar comprises a 45-minute presentation and a 15-minute Q&A, and it’s free to attend. You can watch all videos on the ELISA Project Youtube Channel ELISA Seminar Series Playlist here.