Linux is used in all major industries because it can enable faster time to market for new features and take advantage of the quality of the code development processes. Launched in February 2019, the Enabling Linux In Safety Application (ELISA) Project works with Linux kernel and safety communities to agree on what should be considered when Linux is used in safety-critical systems. The project has several dedicated working groups that focus on providing resources for system integrators to apply and use to analyze qualitatively and quantitatively on their systems.
The Working Groups have two main focuses – the horizontal Working Groups include Safety Architecture, Linux Features, Tool Investigation, Open Source Engineering Process, and Systems as well as vertical use case based Working Groups in Aerospace, Automotive, and Medical Devices domains.These Working Groups collaborate to produce an exemplary reference system. Linux Features, Architecture and Code Improvements should be integrated into the reference system directly. Tools and Engineering Process should serve the reproducible product creation. Medical, Automotive, Aerospace and additional future WG use cases should be able to strip down the reference system to their use case demands.The Project’s Technical Steering Committee (TSC) oversees the Working Group activities and coordinates cross Working Group collaboration to drive the technical direction of the Project. You can interact with the TSC by subscribing to its public forum and attend its biweekly meeting that’s open to the public by default.
To kickoff 2024, ELISA hosted an annual Working Group Update where all of the leads share a quick overview, milestones achieved and plans for the new year. The update meetings, which was hosted online for a few hours over two days, was open to the public. If you missed the meeting, the videos can be found on-demand on a new Working Group playlist on the ELISA Youtube Channel.
Each week, we’ll feature a new Working Group video and details for how to get involved in meetings and join the discussions. Today, we’ll kick off the blog series with a 10-minute project overview by Philipp Ahmann, Chair of the ELISA Project Technical Steering Committee and Technical Business Development Manager at Robert Bosch GmbH.
ELISA is open to everyone. Anyone can develop and contribute code, get elected to the Technical Steering Committee, or help steer the project forward in any number of ways.
Written by Anna Hermansen, Researcher and Ecosystem Manager for Linux Foundation Research
In the ever-evolving landscape of software development, the integration of open source software (OSS) has become ubiquitous, fostering innovation, efficiency, and collaboration. However, this adoption comes with its own challenges, particularly when it comes to complying with open source licenses. A recent report by the Linux Foundation’s Ibrahim Haddad, titled Open Source License Compliance: Challenges Ahead, sheds light on the intricacies involved in navigating this complex terrain. Below are a few key insights from this report:
The cornerstone of open source license compliance lies in adhering to copyright notices and fulfilling license obligations when incorporating OSS into products or services. This is no small feat, considering the diverse range of licenses, varying terms and conditions, and the rapid pace of software development.
Compliance with OSS licenses is a multifaceted process that begins with identifying all OSS integrated into a product or service. This necessitates a meticulous plan to fulfill the myriad of license obligations associated with each component. The complexity intensifies as organizations grapple with the diverse licensing landscape and the dynamic nature of software development.
To effectively manage OSS license compliance, organizations need robust tools. An advanced Software Composition Analysis (SCA) tool proves indispensable in this regard. These tools boast comprehensive features, aiding organizations in accurately identifying incorporated OSS, understanding licensing requirements, and ensuring adherence to obligations.
Promoting a culture of openness and accountability is key. Beyond tools, organizations can instill a culture of openness, accountability, and collaboration by providing users with visibility into their compliance processes. This transparency not only fosters a sense of responsibility but also enables the organization to address compliance issues or inquiries efficiently.
Organizations can be proactive by integrating compliance into the development process itself. By doing so, organizations reduce the risk of non-compliance while cultivating a healthy internal open source governance culture. This proactive stance ensures that compliance is not an afterthought but an integral part of the software development lifecycle.
Managing OSS license compliance at scale requires leveraging appropriate tools and garnering internal support. This strategic combination helps in mitigating compliance risks and ensures that adherence to license obligations becomes an integral aspect of the development workflow.
The efficacy of SCA tools hinges on their accuracy, consistency, and integration. These tools must navigate complexities, identify all OSS components, and stay updated with the ever-evolving OSS licensing landscape. Achieving this balance is critical for organizations relying on SCA tools to facilitate compliance. To maximize their effectiveness, these tools must seamlessly integrate with the software development lifecycle, which requires automating the scanning of code for open source components and licensing requirements. The integration ensures that compliance is an inherent part of the development process.
Another important tool for compliance is the Software Bill of Materials (SBOM). The adoption of SBOMs is increasing as a means of providing transparency into a software product or service. SBOMs offer insight into component usage, open source licenses, and potential vulnerabilities in the open source components in use, and when standardized in a common format – such as the Linux Foundation’s SPDX project – reduce the workload of collating this information. Despite these advantages, challenges arise when origin and license information of the AI system’s source code is absent, hindering downstream users from generating accurate SBOMs. This gap raises a critical concern, as the inability to trace security vulnerabilities poses a significant red flag in maintaining comprehensive cybersecurity measures.
Auditability is a central challenge for organizations aiming to maintain transparent and comprehensive audit trails of all OSS and license compliance-related activities. The ability to demonstrate adherence to license obligations becomes paramount, especially in the face of
The rise of artificial intelligence (AI)-generated code introduces new challenges to the compliance landscape. Organizations can initially address these challenges by implementing policy options and providing guidance to developers. As AI becomes more prevalent, refining compliance strategies for AI-generated code will be imperative.
As the prevalence of OSS continues to grow, establishing a robust and automated compliance process becomes critical. This not only safeguards organizations from legal repercussions but also shields them from reputational risks associated with non-compliance.
Software developers and business leaders stand to gain invaluable insights from the report, Open Source License Compliance: Challenges Ahead. It offers a comprehensive roadmap, emphasizing the complexities of compliance and the need for advanced Software Composition Analysis (SCA) tools, SBOMs, and integrating compliance into the development process. Following this roadmap reduces non-compliance risks and helps foster a culture of transparency and collaboration.
Moreover, the report tackles emerging challenges, including those posed by artificial intelligence-generated code, and advocates for robust, automated compliance processes. By delving into the intricacies of OSS license compliance, this report equips professionals with the knowledge to harness the benefits of open source innovation confidently while safeguarding against legal and reputational risks. It serves as an indispensable guide, ensuring that both developers and business leaders are well-prepared to navigate the complex terrain of open source software integration.
As Linux continues to be a key component in safety-related applications, Enabling Linux in Safety Applications (ELISA) is an open source project that aims to create a shared set of tools and processes to help companies build and certify Linux-based safetycritical applications and systems. Launched in February 2019, ELISA works with Linux kernel and safety communities to agree on what users should consider when using Linux in safety-critical systems.
In 2023, ELISA increased the technical resources created for the Linux community, including a Seminar Series of no-cost, on-demand videos that provide overviews of a special focus and project workshops for community members who are interested in advancing the milestones and goals of the project. The ELISA Seminar series hosted sessions that many organizations hosted, including Red Hat about an open source tool, tentatively named Basil, for tracing requirements, code, and tests; AMD about Xen safety certification; the Linux Foundation with AlektoMetis about automating adherence to safety profiles after fixing vulnerabilities; and the Boeing Company about DO-178C Level D certified Linux and NASA.
Two in-person workshops in Berlin and Munich brought together industry thought leaders and open source community members to discuss all safety-related issues, challenges, and next steps for the project. The project has several dedicated Working Groups (WGs) that provide resources for system integrators to apply and use to qualitatively and quantitatively analyze their systems:
Aerospace WG is busy surveying aerospace’s state of the art on using Linux and the associated certification approach and equivalent Design Assurance Level and identifying the challenges to adopting Linux in aerospace and candidate use cases using Linux.
Architecture WG is adopting the ks-nav tool set to implement and expand the STPA approach within the kernel.
Linux Features WG analyzed the potential and challenges of real-time safety-critical systems and presented their work at the Embedded Open Source Summit.
Medical Devices WG set out to discover the Linux kernel subsystems that OpenAPS used, shared key findings, and upstreamed the workload tracing guide.
Systems WG shared the work on creating a reproducible example system consisting of Linux, Xen, and Zephyr on real hardware at the Linux Plumbers Conference.
To kick off the new year, ELISA Working Group leads will be giving an annual update next week. The updates will include the following topics:
A recap of milestones in 2023
Current focus and activities
What’s coming up in 2024 and areas and opportunities for collaboration
Onboarding resources and how to get involved
This is a great opportunity to get up to speed with what each of the Working Group is working on and how you can participate and contribute this year. For more details and to register to attend please click here: https://elisa.tech/event/working-group-annual-updates/.
The 2023 World of Open Source: Japan Spotlight report, featuring a foreword by Noriaki Fukuyasu, VP of Operations for the Linux Foundation in Japan, offers a thorough and insightful analysis of the current state and trends of open source software (OSS) in Japan. Authored by Adrienn Lawson and Stephen Hendrick of Linux Foundation Research, this report is pivotal in understanding the dynamics of Japan’s involvement in the OSS arena.
Fukuyasu-san, in his foreword, sheds light on Japan’s distinctive role within the global OSS framework. He emphasizes the importance of comprehending how Japanese organizations and the wider community engage with OSS regarding usage and development and their leadership roles within this space. He provides a relevant backdrop to the report, highlighting Japan’s unique contributions and challenges in OSS.
This report is an invaluable resource for anyone keen to grasp the depth and breadth of Japan’s OSS landscape. It highlights the country’s evolving role in the global OSS community, offering a rich, survey-based exploration into how Japan contributes to, consumes, and leads in the world of open source software. Whether you are a developer, an executive, a policy maker, or simply an OSS enthusiast, this report is a must-read to understand the multifaceted nature of OSS in Japan and its implications for the global technology ecosystem.
This analysis reveals a dichotomy of findings, juxtaposing Japan’s alignment with global trends against its unique challenges and opportunities within the OSS ecosystem. The report offers a dual perspective on Japan’s OSS journey, shedding light on its achievements and highlighting areas for improvement.
Adoption rates and security perceptions vs. regulatory and knowledge barriers
High OSS adoption: Japan’s OSS adoption rate at 82% closely aligns with the global average, indicating robust engagement with OSS.
Contrast with challenges: Despite this high adoption rate, Japanese organizations grapple with regulatory compliance and a lack of understanding of OSS nuances. Concerns about quality, security, and intellectual property further complicate this landscape.
Trust in security vs. contribution challenges
Security confidence: 62% of Japanese organizations trust OSS to be more secure than proprietary alternatives, reflecting strong confidence in OSS security.
Hesitation in contributions: This trust contrasts with the challenges in contributing to OSS, shaped by cultural and organizational factors and a lack of incentives for contribution.
Diverse contributions vs. legal and IP hurdles
Broad engagement: Japan’s OSS community actively contributes beyond coding, including issue reporting and documentation.
Legal barriers: Intellectual property, legal concerns, and complex licensing issues are significant barriers to deeper OSS engagement.
Recognizing OSS benefits vs. underappreciation of non-technical benefits
Strategic advantages acknowledged: Japanese organizations recognize the strategic benefits of OSS, such as improved productivity and innovation.
Non-technical benefits overlooked: There remains an underappreciation of the non-technical benefits of OSS, like community building and cultural improvement.
Policy and training shortcomings: an area for growth
Lack of structured policies: The absence of structured policies and comprehensive training programs in Japan highlights a critical area for development.
Actionable insights for a thriving OSS ecosystem in Japan
Establishing Open Source Program Offices
Role of OSPOs: Establishing Open Source Program Offices (OSPOs) can provide clear guidelines, ensure compliance, and foster a culture of open source contribution within organizations.
Strategic implementation: OSPOs can act as organizational strategic centers to streamline OSS adoption, contribution, and policy development.
Enhancing security in OSS
Prioritizing secure development: Enhancing security practices within OSS projects can alleviate concerns and encourage broader adoption.
Collaborative security efforts: Organizations can collaborate on shared security initiatives, benefiting the wider OSS community.
Expanding educational initiatives
Bridging the knowledge gap: Expanding OSS education and training programs can bridge the understanding gap and illuminate the full spectrum of OSS advantages.
Community and academic partnerships: Collaborations with academic institutions and community groups can further enhance OSS knowledge and skills.
Promoting OSS contributions
Boosting the ecosystem: Encouraging the open-sourcing of internal tools and company products can significantly contribute to the health of the OSS ecosystem.
Recognition and rewards: Implementing recognition systems for OSS contributions within organizations can incentivize active participation.
Tackling legal and licensing challenges
Legal and licensing support: Addressing legal and licensing issues can empower more organizations to engage in OSS projects confidently.
Educational programs on licensing: Providing detailed educational resources on OSS licensing can demystify legal complexities for organizations.
Call to action
We hope this report encourages stakeholders across Japan to realize the full value of open source software and the communities supporting it. Whether you are a developer, an IT professional, a policy maker, or simply an enthusiast of technology and open source culture, this report offers a first-of-its-kind perspective into how OSS is shaping the technological landscape in Japan and how it compares and contributes to the global context.
To get involved, consider the following steps:
Educate yourself: Start by reading the full report to understand the current state of OSS in Japan. Knowledge is power, and understanding the landscape is the first step to making a difference.
Engage with the community: Join local and online OSS communities. This week, Open Source Summit Japan is taking place in Tokyo, which is the forum of choice for engagement. Participating in forums, attending meetups, and contributing to discussions can provide practical insights and networking opportunities.
Contribute to projects: Whether you’re a coder, a documentation specialist, or a tester, your skills can contribute significantly to various OSS projects. Find a project that aligns with your interests and skills, and start contributing.
Advocate for OSS in your organization: If you’re in a position to influence your organization’s software choices, advocate for adopting OSS and supporting OSS policies and training.
Educational and professional development: Continuously seek opportunities to learn more about OSS, whether through formal education, workshops, or self-guided learning. LF Research is a great place to start!
ISO PAS 8926 “Road vehicles – Functional safety – Use of pre-existing software architectural elements” has been approved by the ISO community. This achievement represents a recognition of the work done in the last 2 years by ISO Sub-Group experts from multiple organizations / delegation to include the evaluation of pre-existing complex software for Functional Safety without losing the original ISO 26262 backbone.
The goal of this talk is to provide an overview of ISO PAS 8926 content and its connection with the current ISO 26262 second edition. Moreover, it will be the opportunity to introduce at a high-level the ISO 26262 initiatives related to the 3d edition and their planning.
The ELISA Seminar Series focuses on hot topics related to ELISA’s mission to define and maintain a common set of elements, processes and tools that can be incorporated into Linux-based, safety-critical systems amenable to safety certification. Speakers are members, contributors and thought leaders from the ELISA Project and surrounding communities. Each seminar comprises a 45-minute presentation and a 15-minute Q&A, and it’s free to attend. You can watch all videos on the ELISA Project Youtube Channel ELISA Seminar Series Playlist here.
Written by Red Hat’s Luigi Pellecchia, Senior Software Quality Engineer, and Gabriele Paoloni, Senior Principal Engineer
Introduction
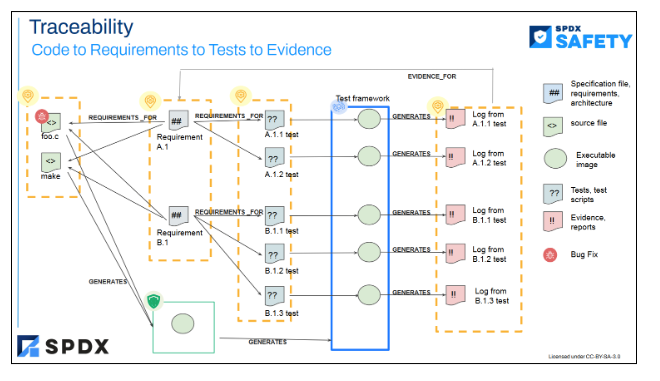
Most of the safety standards across different industry domains are based on requirements definition and associated verification and validation measures to bring the residual risk of failure down to an acceptable level (according to the target safety integrity level). When it comes to claim the systematic capability of SW elements, it is very important to trace requirements down to the specification of such SW elements and to respective tests at different levels (unit tests, integration tests, validation tests).
There are different reasons behind this:
Verification of completeness of safety activities: once we have full traceability in place from requirements to testing, it is much easier to detect if there is a gap between safety requirements, SW specifications and tests.
Assessment feasibility: with traceability in place it is easier to verify the correctness of tests against associated requirements and code specifications.
Maintainability of the safety case against incoming SW changes: if there are SW commits added later, with such traceability in place it is easier to determine the scope of requirements being impacted.
Scalability of the safety case: if there are requirements to be added / removed, with such traceability in place it is much easier to determine the impact on the rest of the safety case (i.e. which code and associated tests to be added or removed)
Complying to safety standards imply a great effort for quality departments.
Quality Engineers have to produce different work items, like Software Requirements, Test Specifications, Test Cases, Test Reports and need to provide evidence and traceability for internal and/or external audits.
Usually that happens across a complex toolchain that involves several tools, and different file formats.
Having the data organized in a structured way helps to keep the situation under control and enables a proper data visualization for the most meaningful picture at any time.
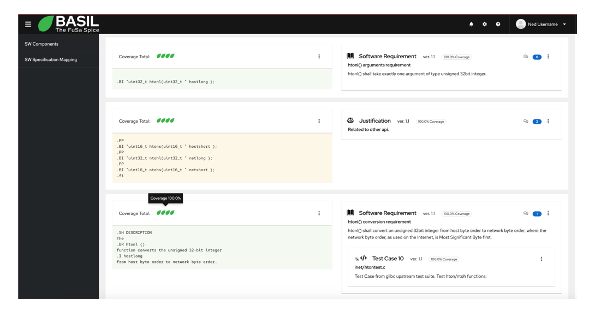
BASIL provides a way to create quality related work items and to relate them to a snippet of the specification document or to a snippet of the source code creating a view that will help you keep track of the status of the analysis.
A snippet is identified in BASIL with an offset and a text. That is because we can have the same text multiple times in a document and we need to be able to distinguish which one we want to use.
When creating a work item and a relationship against a snippet of the target document, the latter will be split in different sections showing the related work items in a 2 columns view.
Work items can be nested in different ways and BASIL provides different views focused on work items with direct mapping against the specification document or source code.
That is because any company can implement its own workflow and define which work items want to create and maintain.
So we can distinguish two different types of relationships in BASIL: direct and indirect.
Direct means the relationship is against the specification document or to the source code.
Indirect means that a work item is related to another work item and the relationship with the specification document or to the source code happens via an hierarchy of work items more less complex.
Each relationship, direct or indirect, will be characterized by a coverage percentage and the overall coverage will take care of all the work item hierarchy that users can specify.
BASIL can be easily integrated in other tool chains thanks to SPDX and a REST api.
All the data can be exported to SPDX in json format and it is possible to interact with the data via http requests as well.
Even if this level of traceability is mostly requested by Functional Safety projects, any software company can leverage BASIL to implement software quality management.
Software, its Specifications and work items are in continuous evolution and BASIL keeps track of this.
So any changes to any work items or relationship will be recorded in the database and it will be possible to see the history of each one.
What happens if the source code or the specification change?
First of all we can test in advance how our work items are affected by any change and we can automatically fix what the tool recognizes as a warning.
A warning means that a particular snippet still exists in the target document or source code, however it does in a different position (offset). We can set BASIL to automatically fix all these warnings.
If a new version of the specification document or of the source code breaks any relationships, BASIL will show them in a separate section and we can adjust the mapping or delete it if no more needed.
BASIL was created to be a collaborative tool and due to that it comes as a web application and It provides also support for comments.
BASIL was developed by Red Hat during the first stages of RHIVOS (Red Hat In Vehicle Operating System) certification story and was presented to the Elisa community in June 2023 during the workshop we had in Berlin. Thanks to the interest of the community we published it as an open source project in the Elisa GitHub repository in October 2023.
Started as a static html report of test mapping software components, it became little by little a dynamic tool that today implements state of art web technologies like REACT and PatternFly and it also comes with an e2e test suite in Cypress and a unit test suite for the REST api written in python.
Written by Philipp Ahmann, Chair of the ELISA Project TSC, and Kate Stewart, Vice President of Dependable Embedded Systems at the Linux Foundation
On October 16-18, ELISA Project gathered at the Red Hat Munich office for an in-person workshop. The event had a great mix of attendees, including both familiar faces and first-time participants, with representatives from non-member companies such as Canonical, Volvo, MBition, Harman, and Valeo. While the workshop was primarily focused on automotive companies, there was also one participant from NASA.
Discussions centered around the core part of Linux, with a need to define what constitutes a core or minimal configuration. It was suggested that distro providers be consulted to determine their kernel configurations. The topic may continue in the architecture working group. A guide and methodology to strip down the kernel to a smaller use case and system-adjusted setting could also be useful.
A major part of the workshop was the discussion around BASIL, a new tool for tracing requirements code and tests that was proposed in the Berlin workshop earlier in the year. Introduced by Red Hat and open sourced just before the event, it has gained interest among other members, including SUSE. SUSE presented their approach on Automotive SPICE SWE processes for complex Open Source Software to get an argumentation around QM state of Linux and components in use of these systems. It is seen as promising by others and will be taken forward. It can be a path towards quality management argumentation of Linux systems.
Nvidia presented a more technical discussion on the kernel level, with a systematic approach to using the Linux kernel in safety scenarios. This was also interesting for Windriver and Elektrobit. The idea is to have a shared list of risk factors and potential interference between system elements. It is a bit of a direction like CVE to CWE if you want to compare it to security.
A session about the SPDX-SIG on Safety focused on requirement traceability with code and tests and gave a good fit to the discussions around BASIL. This was in line with the ELISA’s discussions around enhancing SBOMs to support safety argumentation and evidence.
Sessions were held on how to catch up newcomers, and understand member needs, the ELISA big picture, outreach to adjacent communities, and current challenges to comply with different aspects of the ISO26262 were held as well.
The workshop concluded with a strategy and path towards 2024. ELISA will take a stronger driver towards tools and documentation, with good documentation around PREEMPT_RT being one of these elements. It is further important to show the results so that others can better understand where ELISA is reaching and where it fits into their industrial use cases.
Overall, the workshop was a great success, with many interesting discussions and presentations. The ELISA looks forward to the next workshop and continuing to drive innovation in the Linux ecosystem.
Testimonials
“I am thrilled to have attended the ELISA workshop in Munich, where I gained valuable insights into the complexities of achieving functional safety for Linux, particularly in the automotive industry. The engaging presentations and collaborative discussions with industry experts highlighted the importance of strong collaboration in addressing this challenge.” – Bertrand Boisseau (Canonical)
“I found the ELISA workshop to be very educational and engaging. The speakers were really skilled and had a great understanding of both safety and Linux aspects. I will closely follow ELISA and hope to engage with more OEM presence” – Robert Fekete (Volvo Cars)
Wondering when and where the next ELISA workshop will be held? Keep an eye on upcoming ELISA events.
Interested in getting involved in ELISA? Introduce yourself, ask a question and follow along on Technical Forum, check out the Working Groups and start participating.
Last week, developers from around the world traveled to Richmond, Virginia for the annual Linux Plumbers Conference. Hosted at the Omni Richmond Hotel on November 13-15, the event was mostly in-person with a live-streaming element for those who couldn’t make it.
Philipp Ahmann, Product Manager for Embedded Open Source at Robert Bosch GmbH and Chair of the ELISA Project Technical Steering Committee (TSC), was at the event and gave presentation titled, “Putting Linux into Context – Towards a Reproducible Example System with Linux, Zephyr & Xen.” You can find his presentation video and PPT below:
Demos on embedded systems using Linux are plentiful, but when it comes to reproducing them, things get complicated. Additionally, on decent embedded systems Linux is only one part of the system and interacts with real-time operating systems and virtualization solutions. This makes reproduction even harder.
Within the Linux Foundation’s ELISA project, we started to create a reproducible example system consisting of Linux, Xen, and Zephyr on real hardware. This is the next step after we achieved a reproducible system with a pure Linux qemu image.
The idea is to have documentation, a continuous integration including testing, which can be picked up by developers to derive and add their own software pieces. In this way they should be able to concentrate on their use case rather than spending effort in creating such a system (unless they explicitly want this). We also show how to build everything from scratch. The assumption is that only in this way it is possible to get a system understanding to replace elements towards their specific use cases.
We had challenges finding good hardware, tools, freely available GPU drivers and more and we are still not at the end. A good system SBOM is also creating additional challenges, although leveraging the Yocto build system has provided some advantages here.
While we are setting up the first hardware with documentation from source to build to deployment and testing on embedded hardware, we aim to have at least two sets of all major system elements like Linux flavor, a choice of virtualization technique, real-time OS and hardware. Only when software elements and hardware can be exchanged, we identify clear interfaces and make a system reproducible and adoptable.
Open Questions are:
What will be a good next hardware to extend this PoC scope?
Where do open source, security, safety, and compliance come best together?
Which alternative real-time operating systems and virtualization should be incorporated?
The current stage of space exploration has brought with it an increase in the complexity of systems deployed, in the number of players involved, and in the need for autonomy. This video describes two efforts taking place at NASA to help on that front. One the one hand, the use of runtime monitoring with Ogma and Copilot makes it possible to assure applications that are otherwise too costly to verify formally or test fully.
On the other hand, the use of Kaiaulu to process information about version control systems and issue trackers facilitates providing evidence of compliance with software engineering requirements, and to minimize deviations from the software plans. We believe that, together, they can enable more complex autonomous systems in space applications and shorten the time to that it takes systems to be put in production.
The ELISA Seminar Series focuses on hot topics related to ELISA’s mission to define and maintain a common set of elements, processes and tools that can be incorporated into Linux-based, safety-critical systems amenable to safety certification. Speakers are members, contributors and thought leaders from the ELISA Project and surrounding communities. Each seminar comprises a 45-minute presentation and a 15-minute Q&A, and it’s free to attend. You can watch all videos on the ELISA Project Youtube Channel ELISA Seminar Series Playlist here.
This blog originally ran on the Linux Foundation EU Newsroom. For more content like this, click here.
Linux Foundation Europe proudly hosted its first annual Member Summit! This milestone event marked its inaugural year, bringing together LF Europe participants for an unforgettable gathering. The summit served as a groundbreaking platform for fostering collaboration, open innovation, and strategic partnerships among individuals and organizations in the private and public sectors. All participants worked collectively to advance digital transformation through the lens of open collaboration. This blog recaps the key moments and must-see sessions from the 2023 Member Summit.
The event commenced with an insightful keynote address by Gabriele Columbro, General Manager of Linux Foundation Europe and Executive Director of FINOS. He provided a comprehensive overview of LF Europe’s current state and future prospects, setting the stage for what is to come.
Luka Mustafa, Founder and CEO of IRNAS Institute for Development of Advanced Applied Systems, delved into the vital issue of wildlife protection. He explained how open source technology, particularly Zephyr RTOS, plays a crucial role in creating OpenCollar animal trackers and sensors. These innovative devices are designed to combat poaching and protect endangered species.
A panel discussion featuring Rimma Perelmuter (VP of Strategic Growth of FINOS & Linux Foundation Europe), Mark Lane (Head of Software Engineering Centre of Excellence, Lloyds Banking Group), Lucian Balea (Deputy Director of R&D and Open Source Director, RTE), Philippe Ensarguet (VP of Software Engineering, Orange) and Philipp Ahmann (Product Manager, Bosch) delved into the role of open source collaboration in driving digital transformation across various industries. They discussed how open source initiatives can address common challenges and foster industrial growth and sustainability in Europe and beyond.
Representatives from various projects, including Sylva, OpenNebula, LF Energy, OpenWallet Foundation (OWF), Agstack, Servo, and RISE, provided updates on their respective initiatives. These projects spanned a wide range of fields, from telecommunications to energy systems, agriculture, and web rendering engines, highlighting the diverse impact of open source technologies.
The LF Formation Team and Mirko Boehm (Senior Director, Community Development, Linux Foundation Europe) explored options for project setup and the advantages of hosting projects within Linux Foundation Europe.
Hilary Carter (SVP, Research and Communications, Linux Foundation) discussed two Europe-focused research reports,, highlighting their significance to Europe in terms of sustainability, contribution, and security.
Hilary Carter and Mirko Boehm shared key outcomes from Open Source Congress which took place in Geneva in July. The talk described the origins of the gathering, the issues on the agenda, and the current state of global collaboration across open source organizations.
Mirko Boehm followed with an update on European Union (EU) policies impacting open source and the technology industry. This session shed light on the evolving regulatory landscape and its implications for the open source community.
Robert Reeves (VP of Strategic Partnerships, Linux Foundation) emphasized the importance of strategic partnerships in advancing the goals of the Linux Foundation, and encouraged prospective partners to join us in supporting our mission.
A lively panel discussion tackled the significance of open source AI, its benefits, risks, and role in EU policy. The discussion was led by industry players and policymakers Justin Colannino (Director, Developer Policy and Counsel GitHub), Astor Nummelin Carlberg (Executive Director, OpenForum Europe), Ibrahim Haddad (Executive Director, LF AI & Data and PyTorch Foundation), Sachiko Muto (Chairman, Senior Researcher, OpenForum Europe, RI.SE), and Stefano Mafulli (Executive Director, Open Source Initiative)
The event concluded with Gabriele Columbro providing insights into the future of Linux Foundation Europe, setting the stage for further innovation and collaboration.
https://youtu.be/vjUSkbbCmss?feature=shared
Attendee Reception
LF Europe members were treated to an exclusive reception at the Guggenheim Museum Bilbao, featuring a special celebration for the Linux Foundation Europe’s 1st anniversary. The event included a cake-cutting ceremony, a sumptuous array of foods and drinks, and an opportunity for attendees to explore the museum’s exhibits.
The Linux Foundation Europe Member Summit 2023 was an informative and inspiring event that brought together leaders, innovators, and enthusiasts from the open source community. It highlighted the pivotal role of open collaboration in driving digital transformation and sustainability across various industries in Europe and beyond. We thank all who joined us, and look forward to reconvening again in the future.
For information about becoming a member of LF Europe, please get in touch with us at info@linuxfoundation.eu.