The Linux Foundation hosted the Embedded Open Source Summit (EOSS), a new umbrella event for open source embedded projects and developer communities to come together under one roof for important collaboration and education, in Prague, Czech Republic, on June 27-30. More than 1,300 people registered for the conference – representing 375 organizations across 56 countries around the globe.
Safety is important to software everywhere human lives are at risk. In these environments, safety standards must be followed to minimize the risk to humans and to follow regulations. Safety standards such as ISO 26262 come with a series of requirements and processes that sometimes clash with well-established Open Source software development practices. How do we reconcile safety certifications and Open Source?
This presentation will provide some insights to answer that question, using the Xen hypervisor as an example. Xen has a micro-kernel design and provides a virtualization solution for embedded and automotive while having a code base small enough to make certifications possible. This presentation will go through the changes to upstream processes that the Xen community adopted during the last 12 months to align community activities with safety-certification requirements. It will discuss any additional changes planned for the near future. The talk will also cover the latest updates from the Xen FuSa working group on MISRA C, traceability, testing, etc. Watch the video below:
Click here for the presentation slides. Click here to view the other videos from the Safety-Critical Software Summit.
The Linux Foundation hosted the Embedded Open Source Summit, a new umbrella event for open source embedded projects and developer communities to come together under one roof for important collaboration and education, in Prague, Czech Republic, on June 27-30. More than 1,300 people registered for the conference – representing 375 organizations across 56 countries around the globe.
The event hosted the Safety-Critical Software Summit, which was sponsored by the ELISA Project, that gathered safety experts and open source developers to enable and advance the use of open source in safety-critical applications. As part of the Summit, Peter Brink, Functional Safety Engineering Leader at Underwriter Laboratories (UL) and Steven H. VanderLeest, Chief Technologist for Boeing Linux at Boeing, gave a presentation titled, “Debating Linux in Aerospace: Objections and Paths Forward.”
Traditionally, safety-critical flight software used in aerospace is closed, proprietary code from a handful of commercial vendors. Although open-source software could provide several benefits, there are significant hurdles that prevent widespread adoption. First, we list some of the potential benefits of open source for safety-critical aerospace applications. Second, we present an overview of the key concepts and standards for flight software. Third, we identify the objections and concerns for using Linux as the avionics real-time operating system, which is software that generally needs the highest levels of assurance. For each objection, we suggest a possible path forward to address the concern.
Click here for the presentation slides. Click here to view the other videos from the Safety-Critical Software Summit.
The ELISA Project Seminar Series focuses on hot topics related to ELISA and its mission. Presenters are members, contributors and thought leaders from the ELISA Project and surrounding communities. To view past presentations, click here.
On July 18, Chuck Wolber, Software Engineer at The Boeing Company presented a seminar titled, “A Development Environment for DO-178C Level D Certified Linux.”
This video features the use of Yocto/OpenEmbedded as a tool for managing a distributed development environment, automated build and test, and ultimately delivering a DO-178C level D certified Linux platform into revenue service. It also touches on generalized aspects of traceability, team dynamics, “day one developer,” and extensibility. Watch the video:
Written by Red Hat’s Gabriele Paoloni, Alessandro Carminati & Maurizio Papini
One of the main challenges in using the Linux Kernel for safety-critical systems is conducting safety analyses in the absence of architectural documentation. As outlined in this article, within the ELISA (Enabling Linux in Safety Applications) Project, we are adopting the STPA approach at the system level. Accordingly, the Safety Architecture Working Group has been actively working on implementing and expanding this approach within the Kernel.
To conduct an STPA-inspired analysis, it is necessary to define “controller” entities, along with their corresponding control actions and feedback mechanisms. The Linux Kernel has already been divided into entities, which are maintained by different individuals based on the MAINTAINERS file.
Therefore, the Safety Architecture Working Group has made the decision to experiment with STPA analysis within the Kernel by treating the various subsystems or drivers (as defined in the MAINTAINERS file) as individual controllers. Within this context, the challenge has been to identify the control actions and feedback mechanisms between the drivers and subsystems.
The ks-nav tool set, comprising two complementary tools, is specifically designed to support the identification of such control actions.
To facilitate this, ks-nav offers subsystem call trees, which visually represent the interactions and dependencies among subsystems, starting from a given symbol. This feature allows users to identify potential interfaces between subsystems or drivers that support relevant control actions within the specific context of the symbol under analysis.
Another key feature of ks-nav is the identification of function call trees, which list functions potentially encountered starting from a given one . Such a feature could be useful to understand the subsystem or driver behavior following the invocation of a given function.
In summary, within the context of a specific symbol, ks-nav is capable of initially highlighting potential candidates for control actions between subsystems and drivers. Additionally, it allows users to “zoom in” on each subsystem as necessary to support expert judgment in semantically specifying the control actions.
To accommodate diverse analysis needs, the tool set supports multiple output formats, including dot, raster images (PNG or JPG), and vector images (SVG), facilitating effective visualization.
Flexibility is emphasized with compatibility across different database management systems (DBMS) like PostgreSQL, MySQL, MariaDB, or SQLite. This enables seamless integration with users’ preferred DBMS or existing infrastructure.
Moreover, ks-nav is able to identify indirect calls, including the x86 retpoline technique, within the kernel code, and deals with compiler code optimization.
By offering function call trees, subsystem call trees, versatile output formats, DBMS compatibility, and indirect call detection, the ks-nav tool set provides a comprehensive and efficient solution for ELISA activities in Linux kernel analysis. It provides users with the necessary tools to explore the kernel’s structure, and make informed decisions.
This initial commit of the ks-nav tool set also ensures fair test coverage, guaranteeing reliability and effectiveness in supporting ELISA activities. It marks a milestone, demonstrating the team’s commitment to continuous improvement and future advancements to refine the tool set and meet evolving needs in ELISA activities conducted by the working group.
All are welcome to try out the tools, send pull requests for improvements and bug fixes on the ELISA GitHub here.
There will also be a dedicated session on how to apply this tool at the upcoming ELISA Berlin Workshop June 20-22. Learn more about the Workshop or register for it here.
The Safety-Critical Software Summit, which takes place on June 27-30, 2023 in Prague, Czech Republic, as well as virtually, as part of the new Embedded Open Source Summit conference is packed with technical content.
As open source is found more and more in safety-critical applications, the need to evaluate open source software that meets safety standards has increased. This event, sponsored by the ELISA Project, gathers safety experts and open source developers to enable and advance the use of open source in safety-critical applications. Check out some of the sessions and add them to your schedule:
Special registration rates are available for small businesses, hobbyists, students and virtual attendees.
Members of The Linux Foundation receive a 20 percent discount off registration and can contact events@linuxfoundation.org to request a member discount code.
Stay tuned by subscribing to the ELISA Project newsletter or connect with us on Twitter, LinkedIn or mailing lists to talk with community and TSC members.
Our objective is to specify a system context and an example set of safety goals for a safety-related system involving the Linux kernel, in order to enable the safety analysis and specification of a set of safety responsibilities that we may assign to the kernel in that context (and possibly other contexts), at a useful level of detail.
By system context, we mean either a concrete system design, or an abstraction representing a class of system designs.
By safety goals, we mean a set of system-level criteria that must be satisfied in order to avoid specific negative outcomes or consequences.
By safety responsibilities, we mean the behaviour or properties that are required to avoid violating the safety goals for the given system context. This may involve cooperation with other safety mechanisms, which are required to operate when it is not possible to avoid violating a high level safety goal.
In ISO 26262 terminology, this is equivalent to defining the assumptions of use (AoU) for Linux (or any FOSS component, or integration of components) as a Safety Element out of Context (SEooC).
You can find more information about this approach and its intended role as part of a wider engineering process in the Refining the RAFIA approach talk from last year’s ELISA Spring Workshop.
Our purpose with undertaking this kind of analysis in ELISA is to describe and provide examples of a method for identifying and documenting the risks associated with using Linux in a given context, and to examine how its existing features may be used to help to identify, control and/or mitigate these risks. The results of this analysis may then be used to derive the safety requirements that should apply for a system using Linux in such a context
For example, certain Linux configurations may help to address some of the risks that we identify, while others – including default kernel configurations – may introduce additional and possibly unacceptable risks (e.g performance optimisations that may have unintended or unpredictable consequences). Some mitigations for these risks may be outside the scope of Linux, involving AoUs on applications using Linux or on other components integrated with Linux as part of an operating system.
The outputs of this process are expected to be:
A description of the system context and safety goals that we have assumed for the purpose of the analysis
A specification of the risks that are considered in the analysis, and any exclusions from scope
Safety responsibilities for both Linux and the other system components identified in the system context, and specific requirements relating to these
Specific scenarios that might lead to these safety requirements being violated, which can be used to derive test cases and fault injections, and to identify where additional mitigations, safety mechanisms and/or requirements are needed to deal with these scenarios
Documents capturing the results of Linux feature analysis (or analysis of other interacting components) that was undertaken as part of the investigation
The OSEP group plans to start by applying this approach to the Automotive working group’s Telltale use case, documenting and refining the process as well as recording the results of the analysis.
We have invited other ELISA working groups and contributors to consider the following:
What other system contexts and safety goals should we consider for analysis?
What specific Linux features or properties should we focus on in our analyses?
How might ELISA working groups collaborate in applying, refining and documenting this process and its results?
Are there any external communities with which we might collaborate?
We would also welcome input from other open source contributors and communities interested in functional safety.
If you would like to get involved or learn more about this approach, please join the OSEP mailing list, where you can also find details of our meetings and how to participate.
Written by Shuah Khan, Linux Fellow at the Linux Foundation and member of the ELISA Project TSC
Key Points
Understanding system resources necessary to build and run a workload is important.
Linux tracing and strace can be used to discover the system resources in use by a workload.
Tracing OpenAPS commands with strace generated detailed view of system activity during the common run and helped with generating flowcharts for normal and error paths when commands detected device busy conditions.
Once we discover and understand the workload needs, we can focus on them to avoid regressions and evaluate safety.
OpenAPS is an open source Artificial Pancreas System designed to automatically adjust an insulin pump’s insulin delivery to keep Blood Glucose in a safe range at all times. It is an open and transparent effort to make safe and effective basic Automatic Pancreas System technology widely available to anyone with compatible medical devices who is willing to build their own system.
Broadly speaking, the OpenAPS system can be thought of performing 3 main functions. Monitoring the environment and operational status of devices with as much data relevant to therapy as possible collected, predicting what should happen to glucose levels next, and enacting changes through issuing commands, emails and even phone calls.
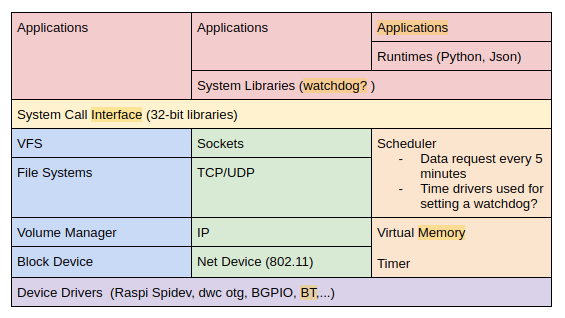
The ELISA Medical Devices Working Group has set out to discover the Linux kernel subsystems used by OpenAPS. Understanding the kernel footprint necessary to run a workload helps us focus on the subsystem and modules that make up the footprint for safety. We set out to answer the following questions:
What happens when an OpenAPS workload runs on Linux and discovers the subsystems and modules that are in active use when OpenAPS is running?
What are the interactions between OpenAPS and the kernel when a user checks how much insulin is left in the insulin pump?
Fine grained view of system activity
As mentioned earlier, the approach we gathered higher level of information about the OpenAPS usage. This higher information doesn’t tell us the system usage by individual OpenAPS commands. For example, watching the brain activity during the entire dinner vs. isolating the activity as we take the first bite of a delicious dessert and enjoy it.
Following up on our previous work, we gathered the fine grained information about individual OpenAPS commands and important use-cases. We used the strace commandto trace theOpenAPS commands based on the process we identified to trace a generic workload which is now in the Linux kernel user’s and administrator’s guide. We traced several OpenAPS commands on an OpenAPS instance running on RasPi managing a Medtronic Insulin Pump. “mdt” in the following text refers to the command provided by https://github.com/ecc1/medtronic:
Get Insulin Pump model (mdt model)
Get Insulin Pump time (mdt clock)
Get Insulin Pump battery (mdt battery)
Get Insulin Pump basal rate schedule (mdt basal)
Suspend Insulin Pump (mdt suspend)
Resume Insulin Pump (mdt resume)
Get the remaining insulin in the Insulin Pump reservoir (mdt reservoir)
Get Insulin Pump temporary basal rate (mdt tempbasal)
We ran these commands in normal mode and under strace to get summary (strace -c ) and complete trace (strace) information. The following shows a few selected commands, their output, trace information, and our analysis of the trace.
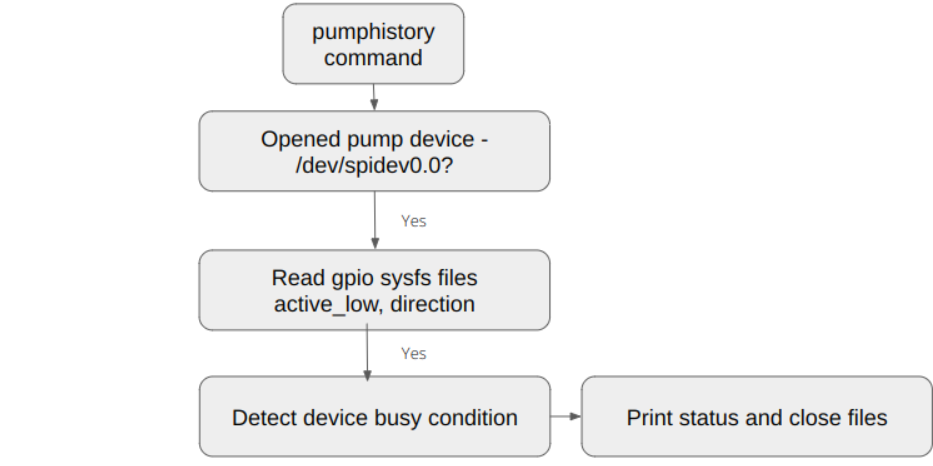
Running the command to get the remaining insulin in the reservoir
mdt reservoir &> reservoir.out # Get the remaining insulin in the reservoir
strace pumphistory -n 1 &> pumphistory.full # full trace
Output from the get pumphistory command
Run pumphistory command
retrieving pump history since 2022-10-12 10:54:03
cannot connect to CC111x radio on /dev/spidev0.0
null
/dev/spidev0.0: device is in use
Process startup (process mgmt)
Open files (fs -> driver sysfs)
Open pump device “/dev/spidev0.0”
Open “/sys/class/gpio/gpio4/active_low”
Open “/sys/class/gpio/gpio4/direction”
Close files (fs -> driver sysfs)
Exit program (process mgmt)
This output shows that the pump busy path is invoked
Pump history command flowchart
Complete strace -c output
2022/10/12 11:54:03 retrieving pump history since 2022-10-12 10:54:03
2022/10/12 11:54:03 cannot connect to CC111x radio on /dev/spidev0.0
null
2022/10/12 11:54:03 /dev/spidev0.0: device is in use
% time seconds usecs/call calls errors syscall
—— ———– ———– ——— ——— —————-
40.92 0.003106 25 120 rt_sigaction
15.91 0.001208 109 11 futex
8.09 0.000614 204 3 clone
7.84 0.000595 59 10 mprotect
7.52 0.000571 190 3 fcntl
5.23 0.000397 44 9 rt_sigprocmask
5.20 0.000395 17 22 mmap2
4.23 0.000321 321 1 readlinkat
3.77 0.000286 13 21 clock_gettime
1.29 0.000098 24 4 brk
0.00 0.000000 0 5 read
0.00 0.000000 0 4 write
0.00 0.000000 0 7 close
0.00 0.000000 0 1 execve
0.00 0.000000 0 1 getpid
0.00 0.000000 0 1 access
0.00 0.000000 0 1 readlink
0.00 0.000000 0 2 munmap
0.00 0.000000 0 1 uname
0.00 0.000000 0 1 1 flock
0.00 0.000000 0 2 sigaltstack
0.00 0.000000 0 1 ugetrlimit
0.00 0.000000 0 5 fstat64
0.00 0.000000 0 1 gettid
0.00 0.000000 0 1 sched_getaffinity
0.00 0.000000 0 1 set_tid_address
0.00 0.000000 0 7 openat
0.00 0.000000 0 1 set_robust_list
0.00 0.000000 0 1 set_tls
—— ———– ———– ——— ——— —————-
100.00 0.007591 248 1 total
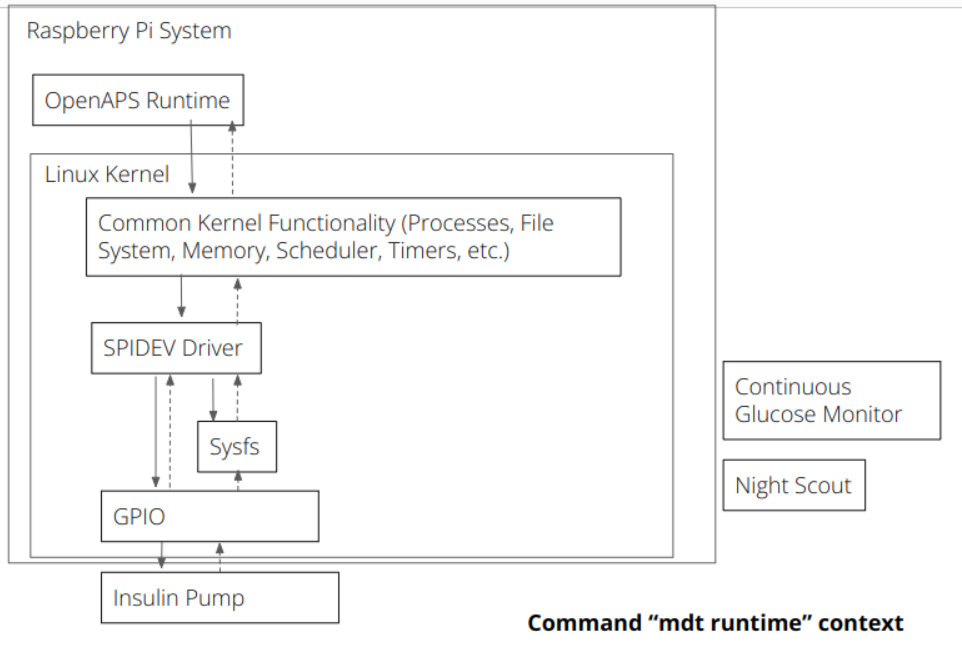
The following diagram shows the run-time context for these commands and their mapping to the Linux subsystems used by them.
System view
The following system view was updated after high level tracing analysis. This system view remains unchanged after the fine grained tracing analysis as expected.
Using strace to trace OpenAPS commands helped us understand the detailed view of system files opened and closed while the commands run. We were able to generate flowcharts for normal and error paths when commands detected device busy conditions. As mentioned earlier, this tracing method gave us insight into the parts of the kernel used by the individual OpenAPS commands.
Credits
The ELISA Medical Working Group would like to sincerely acknowledge Chance Harrison for running the OpenAPS commands and providing information critical for making this effort a successful one.
SPDX-License-Identifier: CC-BY-4.0
This document is released under the Creative Commons Attribution 4.0 International License, available at https://creativecommons.org/licenses/by/4.0/legalcode. Pursuant to Section 5 of the license, please note that the following disclaimers apply (capitalized terms have the meanings set forth in the license). To the extent possible, the Licensor offers the Licensed Material as-is and as-available, and makes no representations or warranties of any kind concerning the Licensed Material, whether express, implied, statutory, or other. This includes, without limitation, warranties of title, merchantability, fitness for a particular purpose, non-infringement, absence of latent or other defects, accuracy, or the presence or absence of errors, whether or not known or discoverable. Where disclaimers of warranties are not allowed in full or in part, this disclaimer may not apply to You.
To the extent possible, in no event will the Licensor be liable to You on any legal theory (including, without limitation, negligence) or otherwise for any direct, special, indirect, incidental, consequential, punitive, exemplary, or other losses, costs, expenses, or damages arising out of this Public License or use of the Licensed Material, even if the Licensor has been advised of the possibility of such losses, costs, expenses, or damages. Where a limitation of liability is not allowed in full or in part, this limitation may not apply to You.
The disclaimer of warranties and limitation of liability provided above shall be interpreted in a manner that, to the extent possible, most closely approximates an absolute disclaimer and waiver of all liability.
We’ve got a few more weeks to go before Linaro Connect, which takes place on April 26-28 at the Park Plaza London Riverbank in London. Once a year, engineers, developers, thought leader and software experts come together for technical sessions and hacking. Discussions focus on the future of open source software, solutions and best practices.
This year, ELISA Project is participating in the Linaro Connect 2023 event and will be presenting an update on the progress in Enabling Linux in Safety Applications (ELISA). The session, which is scheduled on Friday, April 28 from 11:20 – 11:35 am, will be presented by Philipp Ahmann, Product Manager Embedded Open Source at Bosch and Chair of the ELISA Technical Steering Committee (TSC) and Kate Stewart, Vice President of Dependable Embedded Systems at The Linux Foundation and Chair of the ELISA Medical Devices Working Group. Both speakers have extensive experience and knowledge in the fields of embedded systems, open-source software and safety-critical applications.
During the session, attendees will get an overview of the goals and technical strategy of the ELISA project. The presentation will cover the different work groups involved in the project, such as Linux Features for Safety-Critical Systems, Software Architecture, Open Source Engineering Process, Tool Investigation, and Code Improvement. The session will also explore how these work groups interact and contribute to the overall project.
The session will provide information on the methodologies and tools in use, existing challenges, and why the different puzzle pieces are all needed for enabling Linux in safety-critical applications. Attendees will leave the session with a better understanding of where the ELISA project stands today and what comes next. A discussion of how this work can complement other Linaro initiatives will be explored.
Overall, the ELISA project’s attendance at Linaro Connect 2023 offers an intriguing chance to learn more about how the project is making Linux-based safety-critical applications possible as well as vertical use case working groups like Automotive, Medical, and Aerospace. These working groups are aimed at addressing specific challenges related to enabling Linux-based safety-critical applications in their respective domains.
If you’re attending Linaro Connect 2023, don’t miss the ELISA Project talk, especially if you’re interested in functional safety. The session will provide valuable insights into the project’s goals, strategies, challenges, and future plans.
To learn more or register for Linaro Connect, click on the main event website.
Written by Philipp Ahmann, Chair of the ELISA Project TSC (Robert Bosch GmbH) and Sudip Mukherjee, Member of the Tools Working Group (Codethink Ltd)
This article describes how the ELISA Project has enabled Continuous Integration (CI), using the Automotive working group use case as an example. The key goals are to:
Make it easier for others to onboard the project
Experience deliverables from the various working groups
Make the work reproducible and more dependable
Additionally, it describes which elements are part of the pipeline along with the tools involved in the creation and testing of the release images. A remarkable element is that the complete pipeline is coupled to the documented development flow. This means that the CI reproduces the steps a developer would do on a PC.
In this way, it approaches people who are new to safety as well as those which are new to Linux. It is a collaborative approach of multiple working groups within ELISA and should foster more collaboration in upcoming ELISA activities.
Motivational factors that enable the CI
In a collaborative project, people of different interests and technical backgrounds unite to work together. After a successful onboarding process, it is important that contributions and work results become visible to the wider community. They need to be properly basellined and distributed fastly to stakeholders.
A high degree of automation increases the dependability of the development process and reduces failures introduced by human slip. It also gives more time back to developers as they do not have to do everything from scratch.
The ELISA project also relies on external sources for support – for example – the Linux Foundation sister projects Automotive Grade Linux (AGL) and the Yocto Project. The CI guarantees the rebuild whenever updated packages from AGL or Yocto are provided.
In summary, one can say that these demands drive the enablement of the CI within ELISA Automotive WG and put a set of requirements to it:
A entry point for stakeholder with different (technical) background and experience
A respect of different stakeholder interests in the work products
Faster ramp-up for new project contributors
Better and faster integration and distribution of new features and improvements
Automated and dependable software product creation
Extendable testing to validate concepts and assumptions.
With the successful setup of the prototype for the automotive use case, the goal is to scale towards more complex architectures as tackled within the ELISA Systems WG. The basic approach and tools will remain the same in the extension towards new use cases.
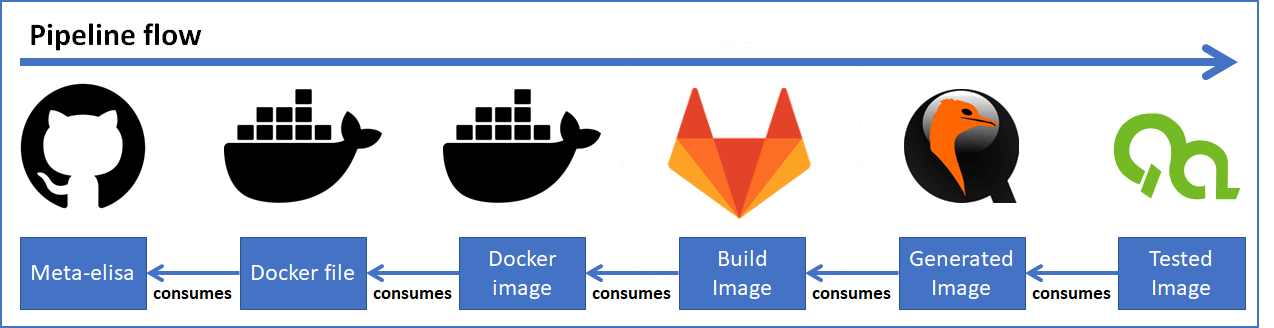
The elements currently involved in the CI include:
All elements are coupled and tied together to build a dependency chain, which makes it easier to automatically detect failures, caused by changes along the elements of the pipeline.
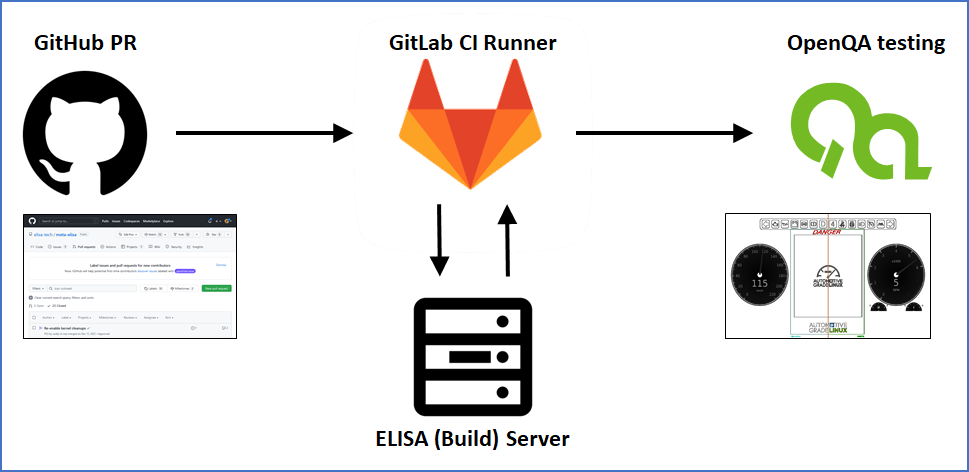
The CI elements and flow within ELISA
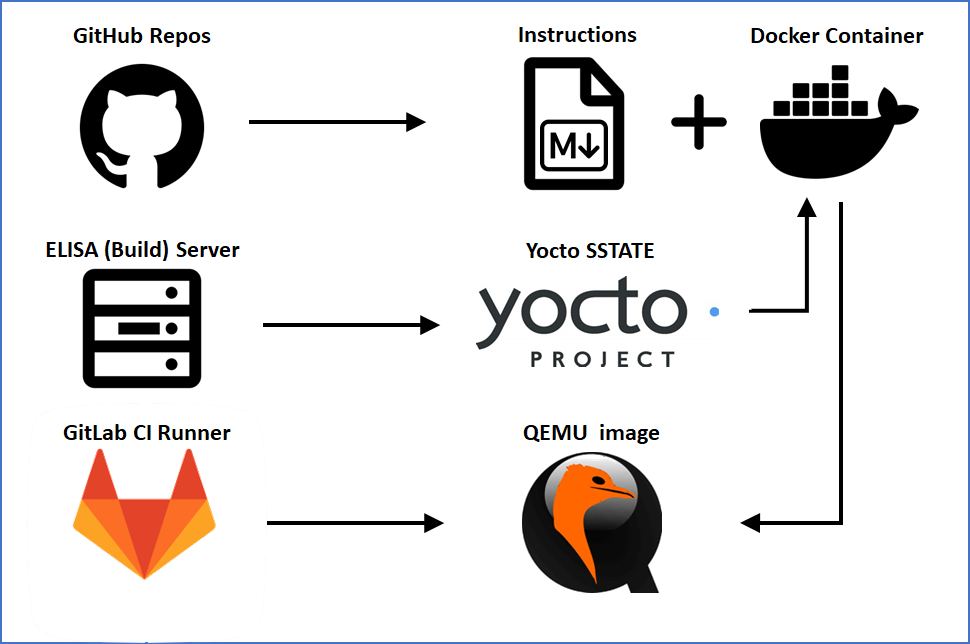
The ELISA Project uses GitLab to run the CI pipeline, which interacts with an ELISA hosted build server (which is also used for other purposes as running tools for code improvement). The build sources are taken from Automotive Grade Linux Gerrit, Yocto Project repositories as well as the ELISA GitHub repositories.
Currently, the generated build artifacts are the kernel and root filesystem for QEMU x86_64 image. It is planned to extend these to additional images for physical hardware in the future.
While the CI is running in GitLab, ELISA is hosting source code and documentation in GitHub. This is the starting point of the CI flow.
The build is triggered on a regular basis once per day to provide a fresh image and check the functionality of the generated image. Due to the usage of cached build artifacts, the longer build times of a full yocto build are reduced to a minimum (in the range of 15 minutes). The generated images are only kept for one day, so that a new download will always have the latest changes included. This further supports the idea of continuous integration. The latest image can be downloaded from the GitLab project packages.
Also a manual trigger of the CI can be done by referencing a GitHub branch of meta-elisa from a PR. In this way a pre-check from changes is possible before formal images are released from the master. It further reduces eventual regressions. To avoid misuse, access to trigger new builds from referenced GitHub forks is restricted to ELISA working group members.
The strong bound of build server to documentation also makes sure that the docker file for manual build is used to create a docker image, which is then used to create the build artifacts for the QEMU image. Also, this is newly created on a regular basis, to make sure that documentation and tool updates will always result in a working image using the latest documentation.
This is needed to achieve the different entry points for the stakeholders who want to try ELISA artifacts or contribute to the project work.
Dependency to the AGL instrument cluster demo
As already mentioned before, but not directly visible from the build flow, is the dependency to the AGL instrument cluster demo. As ELISA collaborates with AGL, it enhances the existing work of AGL and uses it for demonstrating. The results are still a work in progress; therefore the generated meta-elisa layer is not integrated into the formal AGL repositories (yet). Missing this upstreaming causes the risk that the ELISA automotive WG tell-tale demo will break in case AGL makes changes to interfaces used by ELISA. Similar changes can happen for changes in the yocto-poky base.
By building on a daily basis and testing the generated images for the added functionality, it is guaranteed that any breaking change will become directly visible and immediate actions can take place. In these scenarios the latest image will not be deployed for download and analysis of the reported errors can be done.
As a full yocto build can be resource intensive and time consuming the use of cached build artifacts with an enabled SSTATE helps to reduce the build time to a minimum.
Benefits of using Yocto’s SSTATE cache
Building a yocto AGL image from scratch is taking time and a lot of computation performance. At least 100GB of disc space is consumed and a build can easily take several hours to complete even on decent hardware.
In order to reduce the build time and limit the necessary disc space, it is possible to turn on cached build results. The so-called SSTATE is created with the first full build and shared for upcoming builds, demanding to only build deltas. Any change in sources and updates are detected and necessary binaries and their dependencies will be recompiled in case needed.
The generated cache is used within the CI, but can also be used for a local build at a developer PCc.
Additionally, from time to time a new cache is generated to check that the build will also work in case someone builds the system from scratch. Building from scratch can make sense for low network speeds or networks with traffic limitations. This further makes sure that the GitLab pipeline fits to the documentation as much as possible.
GitLab pipeline coupling to the meta-elisa documentation
The GitLab pipeline basically represents the steps which users would take when manually creating the ELISA enhanced demo of the instrument cluster provided by Automotive Grade Linux. As the current version is based on QEMU it is easy to reproduce the demo at a local machine and also to perform automated testing. This is illustrated by transferring the created images to the OpenQA server hosted by Codethink.
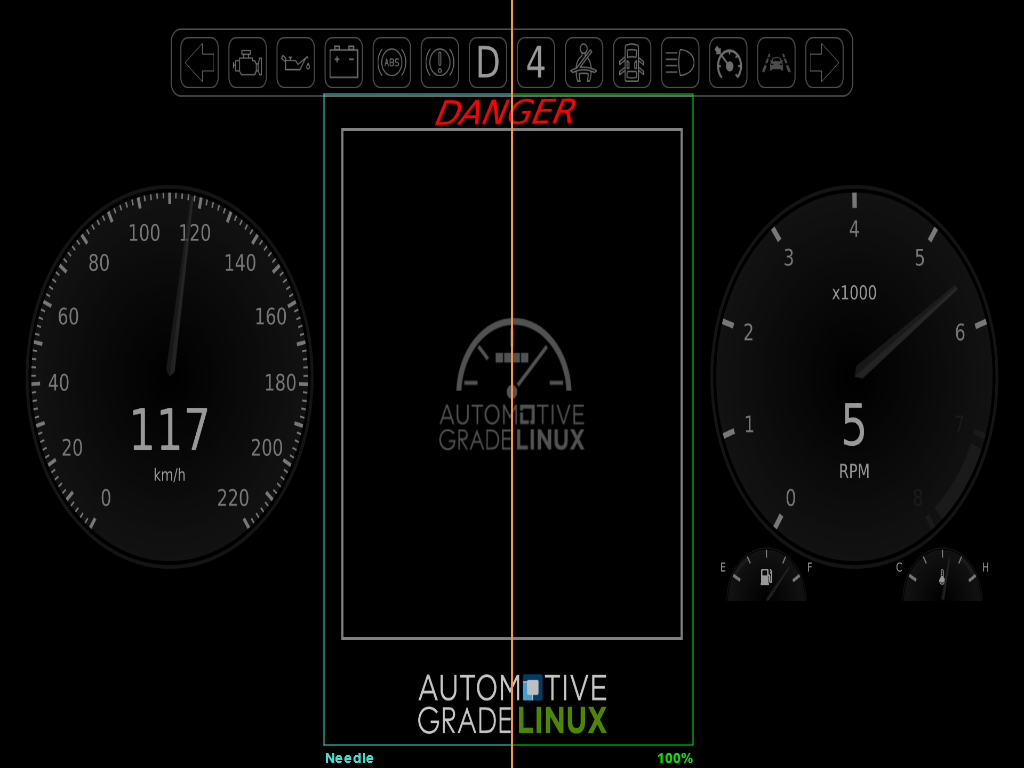
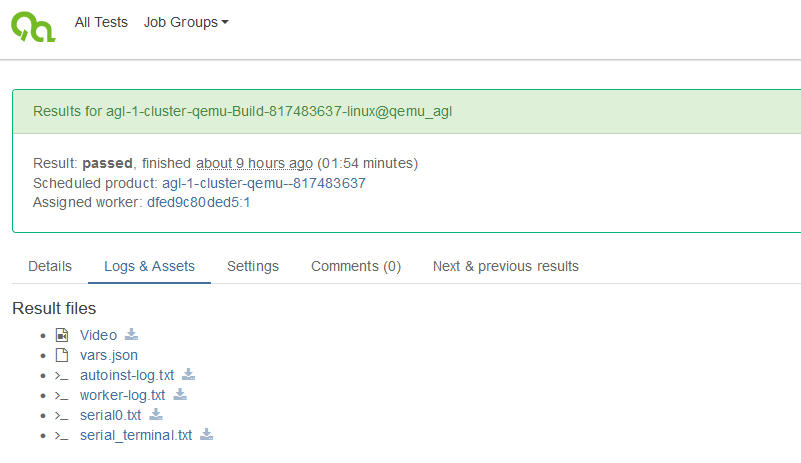
OpenQA testing
It is important to confirm that the build was successful. As the original AGL demo has been enhanced with the Signal-Source-Control application, which also renders additional screen content, it makes sense to do an output comparison. For the meta-elisa demo OpenQA was used as a proven tool to check proper boot and functionality of the code modifications. This should also avoid potential regressions, e.g. due to external dependency or interface changes. An example output of a comparison as generated by OpenQA can be found below.
In the OpenQA tool, the orange divider in the presented screenshot can be moved left and right with the cursor. This makes it easy to identify differences between reference and recent execution. The greenish frame shows the region of interest which is checked for content. The 100% shows the fit ratio.
Additionally, during the test execution a screen recording is performed and further logs such as those from serial terminal are provided.
With this option, a fully automated flow from source repository to generated and tested image is achieved. It is possible that working group members can fork the existing meta-elisa repository on GitHub, do modifications, check that it is built properly using GitLab and that the image remains functionally by checking the OpenQA result. This flow would be completely web based without the demand of even having a development environment setup locally on a PC.
However, this may more be used as an exceptional case. The interaction with the system to understand and learn is rather limited in this scenario. As an intention is to develop the system further and gain a larger understanding of the demand of a safety-critical system with Linux based workloads, there are many more entry points for different levels of expertise and personal interest.
The different entry points to experience the automotive use case
In order to make it easier for new contributors to join the ELISA Automotive WG, the demo has multiple entry points.
Closing the loop to the motivation, the aforementioned entry points fulfill the demands of a collaborative project, where people of different interests come together to collaborate. It is possible to understand the system creation from scratch with an own build from source, or just trace a workload by using the pre-built QEMU images. The development flow is accelerated by providing docker images and cached build artifacts. As the outputs of different pipeline steps are available, debugging gets simplified as well (like checking a native build against a docker build or behavior of the own vs. generated QEMU image).
In summary, a comprehensive documentation (including this post) helps to tailor the pipeline and images to individual demands. Though, to have the best compatibility for exchange with others, the usage of a docker container is recommended.
Docker container for better compatibility of CI and manual reproduction
Taking into account the large number of different host machines and Linux distributions that exist, from practical experience the ELISA CI is providing a docker file as a common base for development. The docker file is used to generate the docker image, which again is used to build the meta-elisa. By providing the docker file and docker image also to others, who want to create a local build on their machine, influence of the underlying Linux distribution is reduced. Documentation about the docker container creation and usage can be found in the wg-automotive github repository. To pull the docker container directly use:
Some general remarks regarding container should be mentioned for competition:
There is still a (limited) dependency to the underlying OS outside the container, as the docker image uses for example the Linux kernel from the host system. However, side effects of missing environment setups, conflicting or overwriting packages are minimized by using the docker container.
Regarding build time and performance the impact of the container could be neglected. The duration and system load during the build with and without container usage was very similar.
The docker file will be kept up to date to reflect demands as per meta-elisa or dependency from yocto or AGL updates. This makes sure to always have the latest features and improvements also for the planned next steps reflected for better reproduction of results.
Outlook and next steps
As an evolution of the use case, activities have been started to enable a reference image of an example architecture including Xen and Zephyr on real automotive hardware. Any result from the automotive as well as other working groups within ELISA should feed into the example architecture tailorable to specific use case demands.
Additionally having a proper software bill of material (SBOM) generation will also enhance the quality of the reproducible demo. It will support upcoming regulations which require an understanding of the content of your software product. As AGL also works on the reproducible build to generate binary compatibility of builds this may be an additional enhancement considered as future activity.
Summary
✔ By setting up the CI with QEMU image deployment to the openQA testing it is possible to quickly track changes and validate code changes for proper appliance along the chain from source to deployment.
✔ Active contributors in ELISA have the chance to check their own commits or pull requests by using a standardized GitHub development flow and start the CI by a two line change in the pipeline reference to the meta-elisa fork and branch commit.
✔ The different entry points and precompiled build results enable interested people to decide to build an image from scratch, use a docker container to reduce environment setup steps and reduce build time to a fraction by taking cached build artifacts from the server.
✔ By provisioning the final QEMU build image, it is even possible to access and boot the generated image without the need of performing an own build.
As all pipeline elements from documentation to later qa testing are dependent on each other and are coupled to an integrated flow. A high degree of dependability and reproduction is achieved with this solution. With a future enhancement of SBOM generation and utilization of reproducible builds project, the system dependability will further be increased. The automated execution supports that aligned development flows are kept and regressions can be tackled before they occur. Best entry points for reproduction of the results are the meta-elisa and wg-automotive docker container documentation in GitHub.
Written by Shuah Khan, Linux Fellow at the Linux Foundation and member of the ELISA Project TSC, and Shefali Sharma, a senior student at the Meerut Institute of Engineering and Technology in India and ELISA Project Mentee in 2022
Key Points
Understanding system resources necessary to build and run a workload is important.
Linux tracing and strace can be used to discover the system resources in use by a
workload. The completeness of the system usage information depends on the
completeness of coverage of a workload.
Performance and security of the operating system can be analyzed with the help of tools such as:
Once we discover and understand the workload needs, we can focus on them to avoid regressions and use it to evaluate safety considerations.
We set out to identify methodology to discover system resources necessary to build and run workload and document the process. Easily available workloads are used to test out methodology and to document the process. This process is intended to be used as a guide on how to gather fine-grained information on the resources in use by workloads.
Within the ELISA project the methodology goes into scaling, by hardening and extending the guidelines in other working groups. The achievements from the Medical Devices Working Group will be taken and put into practice within the Automotive WG use case analysis focusing on safety critical display rendering.
The workload-tracing guide is now available in Linux 6.3 release. It is intended to be used as a guide on how to gather fine-grained information on the resources in use by workloads using strace.