This blog was originally published by Alessandro Carminati, Principal Software Engineer at Red Hat, on his personal blog and is republished here with permission.
Why I Went Down This Rabbit Hole
Back in 1993, when Linux 0.99.14 was released, /dev/mem made perfect sense. Computers were simpler, physical memory was measured in megabytes, and security basically boiled down to: “Don’t run untrusted programs.”
Fast-forward to today. We have gigabytes (or terabytes!) of RAM, multi-layered virtualization, and strict security requirements… And /dev/mem is still here, quietly sitting in the kernel, practically unchanged… A fossil from a different era. It’s incredibly powerful, terrifyingly dangerous, and absolutely fascinating.
My work on /dev/mem is part of a bigger effort by the ELISA Architecture working group, whose mission is to improve Linux kernel documentation and testing. This project is a small pilot in a broader campaign: build tests for old, fundamental pieces of the kernel that everyone depends on but few dare to touch.
In a previous blog post, “When kernel comments get weird”, I dug into the /dev/mem source code and traced its history, uncovering quirky comments and code paths that date back decades. That post was about exploration. This one is about action: turning that historical understanding into concrete tests to verify that /dev/mem behaves correctly… Without crashing the very systems those tests run on.
What /dev/mem Is and Why It Matters
/dev/mem is a character device that exposes physical memory directly to userspace. Open it like a file, and you can read or write raw physical addresses: no page tables, no virtual memory abstractions, just the real thing.
Why is this powerful? Because it lets you:
- Peek at firmware data structures,
- Poke device registers directly,
- Explore memory layouts normally hidden from userspace.
It’s like being handed the keys to the kingdom… and also a grenade, with the pin halfway pulled.
A single careless write to /dev/mem can:
- Crash the kernel,
- Corrupt hardware state,
- Or make your computer behave like a very expensive paperweight.
For me, that danger is exactly why this project matters. Testing /dev/mem itself is tricky: the tests must prove the driver works, without accidentally nuking the machine they run on.
STRICT_DEVMEM and Real-Mode Legacy
One of the first landmines you encounter with /dev/mem is the kernel configuration option STRICT_DEVMEM.
Think of it as a global policy switch:
- If disabled,
/dev/mem lets privileged userspace access almost any physical address: kernel RAM, device registers, firmware areas, you name it.
- If enabled, the kernel filters which physical ranges are accessible through
/dev/mem. Typically, it only permits access to low legacy regions, like the first megabyte of memory where real-mode BIOS and firmware tables traditionally live, while blocking everything else.
Why does this matter? Some very old software, like emulators for DOS or BIOS tools, still expects to peek and poke those legacy addresses as if running on bare metal. STRICT_DEVMEM exists so those programs can still work: but without giving them carte blanche access to all memory.
So when you’re testing /dev/mem, the presence (or absence) of STRICT_DEVMEM completely changes what your test can do. With it disabled, /dev/mem is a wild west. With it enabled, only a small, carefully whitelisted subset of memory is exposed.
A Quick Note on Architecture Differences
While /dev/mem always exposes what the kernel considers physical memory, the definition of physical itself can differ across architectures. For example, on x86, physical addresses are the real hardware addresses. On aarch64 with virtualization or secure firmware, EL1 may only see a subset of memory through a translated view, controlled by EL2 or EL3.
The main function that the STRICT_DEVMEM kernel configuration option provides in Linux is to filter and restrict access to physical memory addresses via /dev/mem. It controls which physical address ranges can be legitimately accessed from userspace by helping implement architecture-specific rules to prevent unsafe or insecure memory accesses.
32-Bit Systems and the Mystery of High Memory
On most systems, the kernel needs a direct way to access physical memory. To make that fast, it keeps a linear mapping: a simple, one-to-one correspondence between physical addresses and a range of kernel virtual addresses. If the kernel wants to read physical address 0x00100000, it just uses a fixed offset, like PAGE_OFFSET + 0x00100000. Easy and efficient.
But there’s a catch on 32-bit kernels: The kernel’s entire virtual address space is only 4 GB, and it has to share that with userspace. By convention, 3 GB is given to userspace, and 1 GB is reserved for the kernel, which includes its linear mapping.
Now here comes the tricky part: Physical RAM can easily exceed 1 GB. The kernel can’t linearly map all of it: there just isn’t enough virtual address space.
The extra memory beyond the first gigabyte is called highmem (short for high memory). Unlike the low 1 GB, which is always mapped, highmem pages are mapped temporarily, on demand, whenever the kernel needs them.
Why this matters for /dev/mem: /dev/mem depends on the permanent linear mapping to expose physical addresses. Highmem pages aren’t permanently mapped, so /dev/mem simply cannot see them. If you try to read those addresses, you’ll get zeros or an error, not because /dev/mem is broken, but because that part of memory is literally invisible to it.
For testing, this introduces extra complexity:
- Some reads may succeed on lowmem addresses but fail on highmem.
- Behavior on a 32-bit machine with highmem is fundamentally different from a 64-bit system, where all RAM is flat-mapped and visible.
Highmem is a deep topic that deserves its own article, but even this quick overview is enough to understand why it complicates /dev/mem testing.
How Reads and Writes Actually Happen
A common misconception is that a single userspace read() or write() call maps to one atomic access to the underlaying block device. In reality, the VFS layer and the device driver may split your request into multiple chunks, depending on alignment and boundaries, in this case.
Why does this happen?
- Many devices can only handle fixed-size or aligned operations.
- For physical memory, the natural unit is a page (commonly 4 KB).
When your request crosses a page boundary, the kernel internally slices it into:
- A first piece up to the page boundary,
- Several full pages,
- A trailing partial page.
For /dev/mem, this is a crucial detail: A single read or write might look seamless from userspace, but under the hood it’s actually several smaller operations, each with its own state. If the driver mishandles even one of them, you could see skipped bytes, duplicated data, or mysterious corruption.
Understanding this behavior is key to writing meaningful tests.
Safely Reading and Writing Physical Memory
At this point, we know what /dev/mem is and why it’s both powerful and terrifying. Now we’ll move to the practical side: how to interact with it safely, without accidentally corrupting your machine or testing in meaningless ways.
My very first test implementation kept things simple:
- Only small reads or writes,
- Always staying within a single physical page,
- Never crossing dangerous boundaries.
Even with these restrictions, /dev/mem testing turned out to be more like diffusing a bomb than flipping a switch.
Why “success” doesn’t mean success (in this very specific case)
Normally, when you call a syscall like read() or write(), you can safely assume the kernel did exactly what you asked. If read() returns a positive number, you trust that the data in your buffer matches the file’s contents. That’s the contract between userspace and the kernel, and it works beautifully in everyday programming.
But here’s the catch: We’re not just using /dev/mem; we’re testing whether /dev/mem itself works correctly.
This changes everything.
If my test reads from /dev/mem and fills a buffer with data, I can’t assume that data is correct:
- Maybe the driver returned garbage,
- Maybe it skipped a region or duplicated bytes,
- Maybe it silently failed in the middle but still updated the counters.
The same goes for writes: A return code of “success” doesn’t guarantee the write went where it was supposed to, only that the driver finished running without errors.
So in this very specific context, “success” doesn’t mean success. I need independent ways to verify the result, because the thing I’m testing is the thing that would normally be trusted.
Finding safe places to test: /proc/iomem
Before even thinking about reading or writing physical memory, I need to answer one critical question:
“Which parts of physical memory are safe to touch?”
If I just pick a random address and start writing, I could:
- Overwrite the kernel’s own code,
- Corrupt a driver’s I/O-mapped memory,
- Trash ACPI tables that the system kernel depends on,
- Or bring the whole machine down in spectacular fashion.
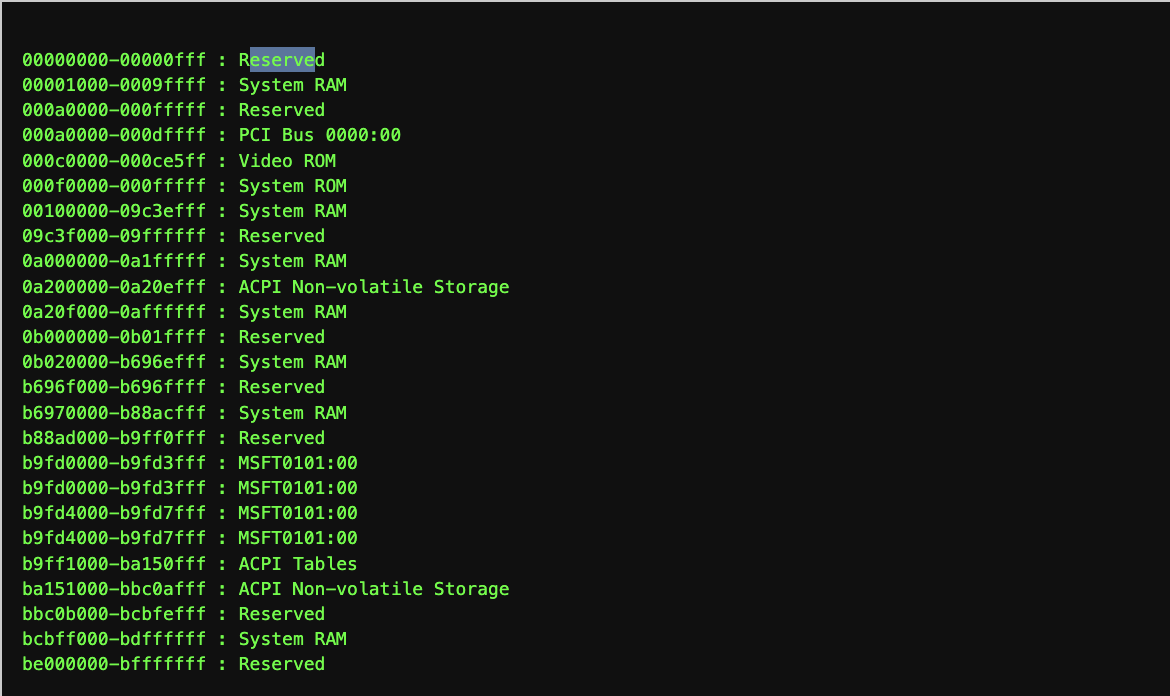
This is where /proc/iomem comes to the rescue. It’s a text file that maps out how the physical address space is currently being used. Each line describes a range of physical addresses and what they’re assigned to.
Here’s a small example: