

elisaproject

Key Insights from the Lund Workshop
Written by Kate Stewart, Vice President of Dependable Embedded Systems at the Linux Foundation, and Philipp Ahmann, Senior OSS Community Manager at ETAS and Chair of the ELISA Project Technical...

Improved system stressing with stress-ng
Stress-ng has a proven track record for stress testing Linux systems and forcing out system bugs. As past of the ELISA Seminar series, Colin King, Principal Engineer at Intel, gave...

Aligning Automotive Standards with Open Source Excellence
Dylan Dawson, Head of Partner Management at Elektrobit Automotive GmbH, gave a presentation about “Aligning Automotive Standards with Open Source Excellence,” at The Safety-Critical Software Summit, which took place on...
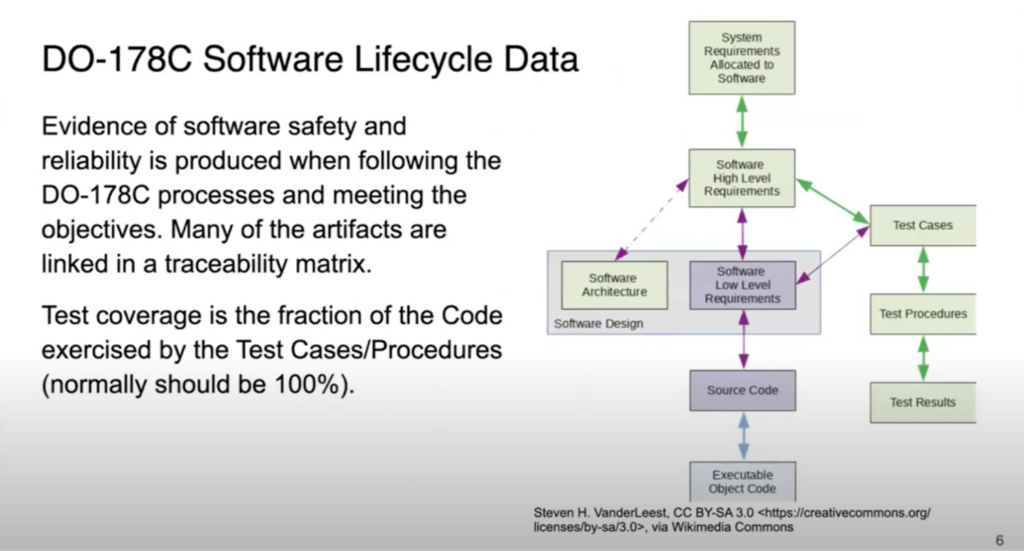
Making Linux Fly: Towards Certified Linux Kernel
Although the Linux operating system has been used widely in many industries, adoption in aerospace has been slow due to the rigorous assurance evidence required as part of flight certification....
Ferrocene: Qualifying the Rust compiler out in the open
Ferrocene is a fully open source toolchain to enable the use of the Rust programming language in safety-critical environments. It is a proper downstream of the main Rust compiler –...

ELISA Project at embedded world
The world of embedded systems is multifaceted – from hardware and software to services and tools. The embedded world Exhibition & Conference brings the entire embedded community together once a year in...
Working Group Spotlight: Automotive
To kickoff 2024, ELISA hosted an annual Working Group Update where all of the leads share a quick overview, milestones achieved and plans for the new year. The update meetings,...