On February 11–12, the ELISA Project community gathered for the 2026 Working Group (WG) and Special Interest Group (SIG) Annual Updates. Over two focused sessions, group leads shared key milestones from 2025, current technical priorities, and what lies ahead in 2026, along with concrete opportunities for collaboration and contribution.
The annual updates serve as a checkpoint for the project: a moment to reflect on progress, align on priorities, and welcome new contributors into the work of advancing Linux in safety-critical systems.
This week we highlight the session on Safety Critical Linux Features by Alessandro Carminati, NVIDIA.
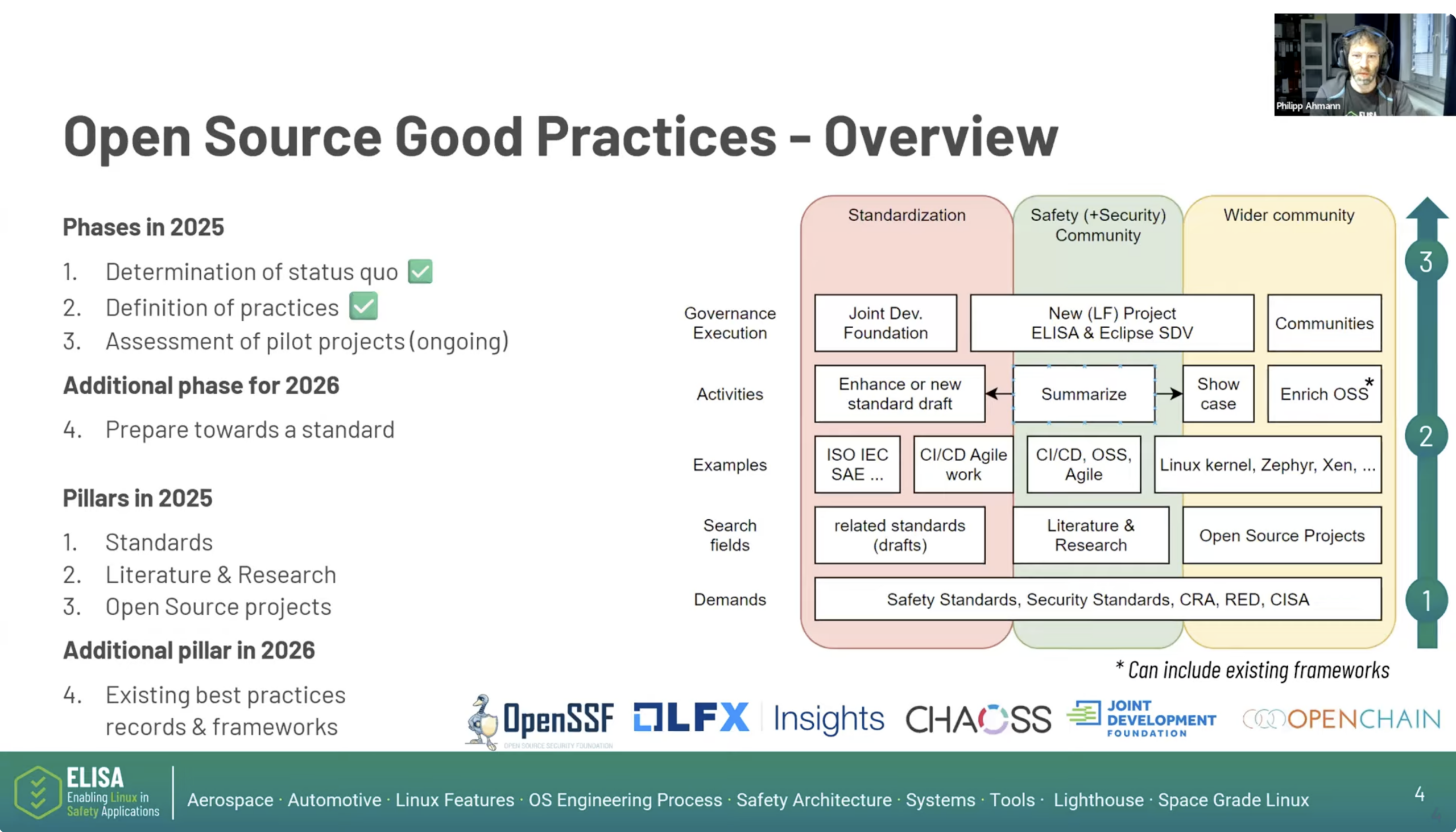
As part of the ELISA Project Working Group and Special Interest Group Annual Updates held on February 11–12, 2026, Alessandro Carminati (NVIDIA) presented the latest progress from the Linux Features for Safety-Critical Systems (LFSCS) Working Group, outlining 2025 activities, current technical investigations, and priorities for 2026.
The LFSCS Working Group approaches Linux from a safety perspective by asking not whether it works, but how it could fail within a safety-critical system. Its role is not to certify systems or build safety cases, but to investigate Linux kernel and, where relevant, user space behavior to identify where safety assumptions may break. The group focuses on areas such as memory isolation, allocation behavior, and process boundaries domains where failures could have real safety implications. These investigations are translated into structured scenarios and reproducible technical questions that can be shared across the open source ecosystem.
Operating as a horizontal working group within ELISA, LFSCS works across domains including automotive, aerospace, and industrial systems. Vertical working groups bring real-world requirements, and LFSCS maps those needs to Linux features, identifying where implementation details or system behavior may challenge safety expectations. This model allows the group to build a foundational understanding of safety-relevant Linux behavior that can be reused and validated across industries.
Key work in 2025:
In 2025, the group focused on several key technical areas driven by emerging questions and contributor input. One major effort examined the concept of a minimal Linux footprint identifying the smallest functional system required for safety-critical deployments by tracing real application behavior and mapping which kernel features are actually used. This work helps reduce system complexity and provides insight into the runtime surface exposed in safety environments. Another central investigation focused on memory isolation, particularly Virtual Memory Areas (VMAs), which are core to process and context separation in Linux. The group analyzed lifecycle behavior, mapping evolution, allocation interactions, and system behavior under stress to better understand isolation guarantees and where flexibility in the system may conflict with deterministic safety expectations. In addition, exploratory topics such as pointer safety models were discussed, reflecting the group’s openness to contributor-driven ideas and emerging areas of interest.
The output of the LFSCS Working Group is primarily investigative and is shared through documentation, workshops, and public discussions to ensure visibility and reuse. The session also emphasized the importance of collaboration, particularly with other working groups, to connect analytical findings with tooling and reproducible validation.
Looking ahead to 2026, the group will continue advancing analysis of Linux features in safety contexts, expanding collaboration across domains, supporting integration with tooling efforts, and encouraging community participation.
The working group meets regularly and welcomes contributors through meetings, mailing lists, and GitHub. This session highlighted how LFSCS is building a deeper technical understanding of Linux behavior in safety-critical systems helping the ecosystem better identify risks and support the adoption of Linux where safety is essential.
Learn more about the ELISA Project and how to get involved.