This blog is written by Alessandro Carminati, TSC member and Linux Features WG Chair at the ELISA Project and an engineer at NVIDIA.
If you ever worked with Linux, you probably heard something like:
“User space and kernel space are isolated.”
Which is true. And also… not entirely comforting.
Because, as Murphy politely reminds us:
“Anything that can go wrong, will go wrong.”
At the ELISA LFSCS working group, we try to look at Linux from a functional safety perspective. That means we are not satisfied with “it usually works”… we want to understand what could go wrong.
At the ELISA LFSCS working group, we try to look at Linux from a functional safety perspective. That means we are not satisfied with “it usually works”… we want to understand what could go wrong.
From Munich: A Suspicious Idea
During the Munich 2025 session, we discussed what we called the linear mapping threat.
The idea is simple:
- Linux keeps a linear mapping of physical memory
- This mapping includes all RAM
- Kernel objects and user pages come from the same pool
So in theory:
A kernel object page could sit right next to a user page.
Not a fault… Not a bug… Just… how memory is laid out.
And that alone raises a question.
Because if a kernel bug causes an overflow, adjacency matters much more than isolation:
- overflow → likely direction → next page
- underflow → possible, but statistically less common
So the interesting case becomes:
kernel page → next → user page
At that point, this was still a hypothesis. A reasonable one… But still a hypothesis.
From Hypothesis to Observation
So we asked:
Can we observe this situation?
Not in theory. Not in diagrams. But in actual memory.
To be clear, not the fault happening… just the fact that Kernel objects pages and userspace pages can sit next to each other.
The Tool (a.k.a. “Let’s Peek at PFNs”)
Initially, the plan was simple:
“Let’s write a kernel module and scan the linear mapping.” Because… that’s what kernel people do. (Maslow’s Hammer: If the only tool you have is a hammer, you tend to see every problem as a nail)
Then came the slightly embarrassing realization:
“Wait… I can already see this from userspace.”
Using /proc/kpageflags.
And suddenly:
- no kernel module needed
- no patching
- no special hooks
Just a userspace tool reading kernel-exposed data.
Small Technical Box: /proc/kpageflags
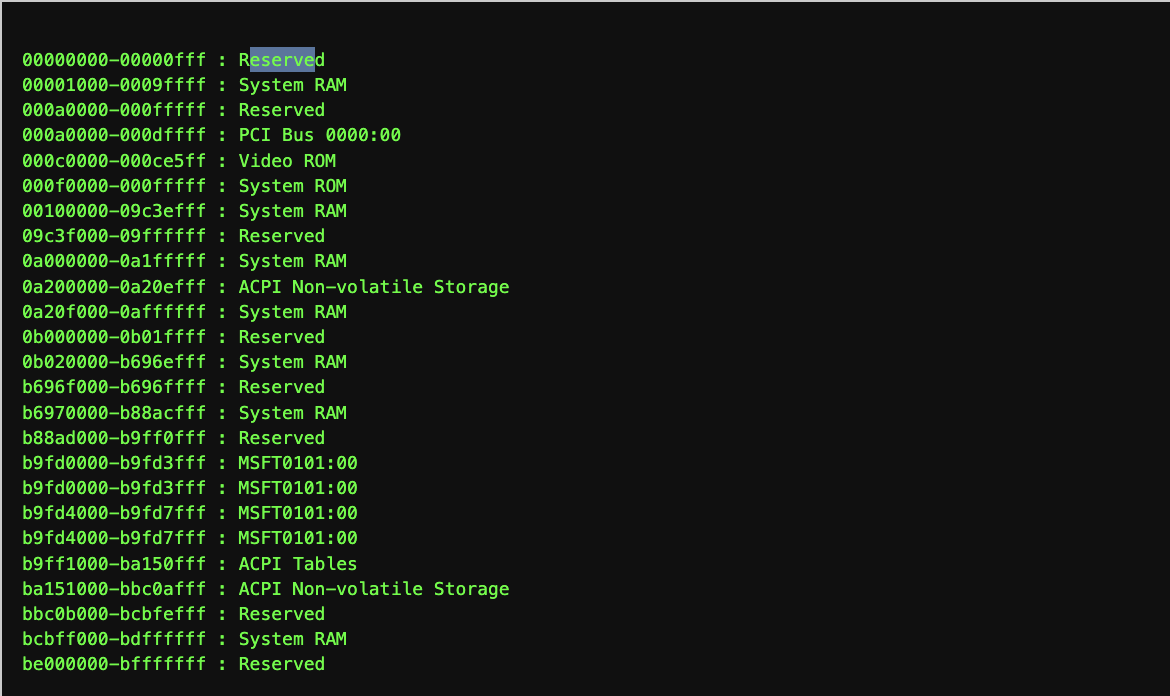
/proc/kpageflags exposes metadata for each physical page frame (PFN).
With it, you can:
- iterate over physical memory
- classify pages (anonymous, slab, huge, etc.)
- build a PFN-level view of the system
In practice, the tool:
- scans PFNs sequentially
- assigns a category per page
- renders a colored raster
Think of it as:
a “topographic map” of memory… where mountains are slab pages and plains are user memory. (Yes, the legend is still under construction.)
First Results: “This Looks… Too Clean”
Using the tool on a real system (x86), results were promising:
- memory looked mixed
- user and kernel pages were interleaved
- adjacency was visible
Good.
But the LFSCS working group set its reference platform as aarch64 many moons ago and when if came to the ARM64 VM we’re targeting:
- almost no user pages
- almost no slab pages
- everything looked… suspiciously clean
At this point, either:
- the tool was wrong
- the kernel was lying
- or the system was too nice
What We Learned (a.k.a. “The Plot Thickens”)
Huge Pages Were Hiding Reality
Disabling THP:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
suddenly changed everything.
Why?
Because:
- userspace sees memory at page granularity (4KB)
- linear mapping may represent the same memory as huge pages
So we had:
fine-grained user memory vs coarse-grained linear mapping view
Disabling THP aligned the two worlds and revealed the real distribution.
Slab Pages Don’t Like Attention
The SLAB flag is only set on compound head pages.
Meaning:
most kernel objects are there… just not explicitly labeled
So the absence of slab in the visualization was… misleading.
The System Was Too Clean
The VM had:
- low workload
- low fragmentation
- limited kernel activity
In short:
not enough chaos to trigger interesting behavior
Forcing Reality (a.k.a. “Adding Some Chaos”)
One missing piece was understanding that:
a real system naturally creates fragmentation a virtual machine… usually does not
So to observe the phenomenon in a controlled environment, we needed to give to the kernel an helping foot.
The approach was to introduce controlled memory pressure and fragmentation using a small kernel-side helper.
The idea is simple:
- allocate many temporary objects
- insert a few persistent objects in between
- free the temporary ones
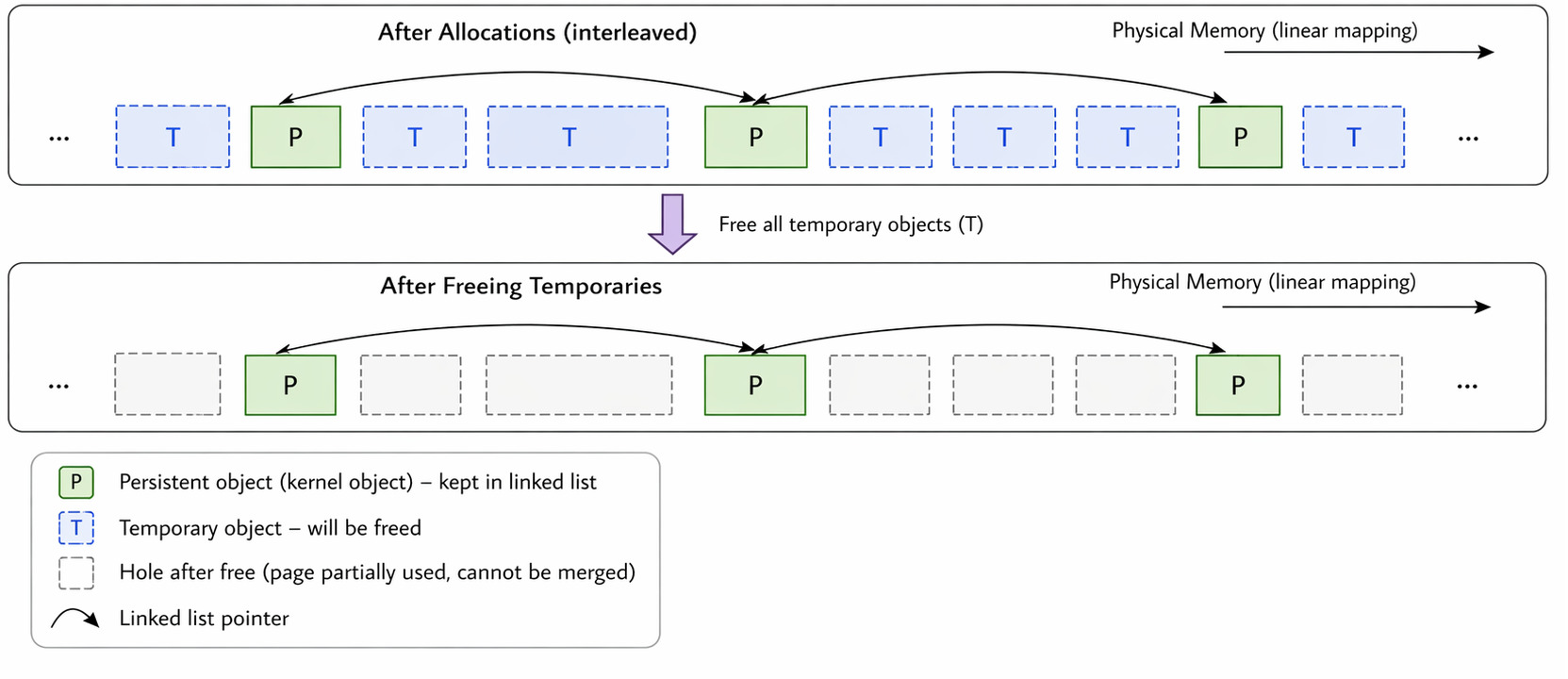
Swiss Cheese Kernel Heap
This leaves behind memory pages that are:
- partially used
- not reclaimable
- and therefore fragmented
This creates a layout where:
kernel allocations are spread across many partially filled pages
Which is exactly the condition needed to increase the chance of:
kernel page → next → user page adjacency
Think of memory like a block of cheese:
- temporary allocations = drilling holes
- persistent objects = small solid parts left behind
After removing the temporary allocations:
you don’t get a clean empty block you get a holey structure the kernel cannot easily compact
The Key Result
After:
- fixing classification
- aligning granularity
- adding controlled fragmentation
We can say:
Kernel and user pages can be physically adjacent. Not always. Not everywhere. But definitely possible.
And importantly: this can happen naturally on a real system while in a VM it may require forcing conditions
Looking Closer (a.k.a. “What Exactly Is Sitting at the Edge?”)
At this point, we knew that: kernel pages and user pages can be physically adjacent. Which is already interesting.
But adjacency alone does not tell us how easy it is for trouble to cross the border.
If the last object in the kernel page ends hundreds of bytes before the page boundary, then an overflow would need to be fairly enthusiastic.
If instead the object ends exactly at the page boundary…
then even a tiny mistake can immediately step into the next page.
So the obvious next question was: “What is actually sitting at the very end of the slab page?”
Teaching the Tool Some Slab Archaeology
The original direct_map_view PoC was good at classifying pages.
The updated version became slightly more nosy.
Given a user page, it now:
- looks at the preceding PFN,
- checks whether that PFN is slab-backed,
- scans the page,
- and identifies the kernel object closest to the end of the page.
Using kmem_dump_obj(), the probe can determine which slab cache owns the object and where the object begins.
In other words: we stopped looking only at pages and started looking at what is actually living inside them.
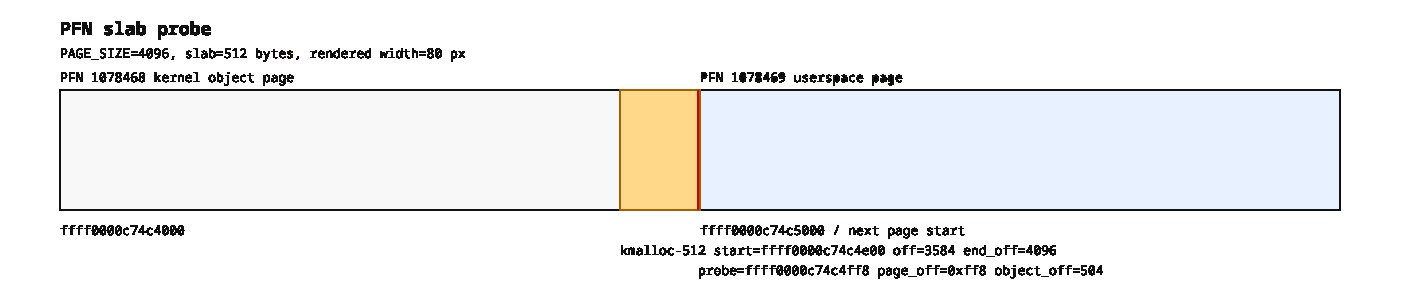
A Typical Result
[ 66.010479] pfn_slab_probe: input_pfn=1078469 checked_pfn=1078468 flags=0xbfffe0000000200
[ 66.010862] pfn_slab_probe: checked PFN 1078468 is slab-backed, scanning [ffff0000c74c4000 - ffff0000c74c5000)
[ 66.011652] slab kmalloc-512 start ffff0000c74c4e00 pointer offset 504 size 512
[ 66.013007] pfn_slab_probe: nearest candidate object at ffff0000c74c4ff8, offset 0xff8 into PFN 1078468The probe did not find an object starting at 0xff8.
It found itself standing 8 bytes before the edge of the page, inside a kmalloc-512 object, at offset 504 from the beginning of that object.
So the math is:
0xff8 - 504 = 0xe00The object starts at 0xe00 and, being 512 bytes long, ends at 0x1000.
Exactly at the page boundary. Which is the memory-management equivalent of parking with the bumper touching the wall.
Turning Logs into Pictures
Because hexadecimal offsets are excellent at convincing computers but less effective with humans, a small script was added to convert the logs into SVG diagrams.
The result is a picture showing:
- the slab page,
- the last kernel object,
- the page boundary,
- and the user page immediately after it.
Sometimes, a drawing is worth several hundred printk()s.
From “Interesting Layout” to “Well… That Escalated Quickly”
At this point, we had demonstrated that:
- a kernel object can sit at the end of a page,
- the next physical page can belongs to a user process.
The next question was unavoidable: “What happens if the kernel writes past that boundary?”
Fortunately for science, and slightly less fortunately for the victim process, we now have a PoC for that too.
The Victim (a.k.a. “The Simplest Program We Could Get Away With”)
The userspace target is a tiny assembly program, available for both:
Its behavior is intentionally boring:
- print the address of a string,
- wait,
- print the string,
- exit.
That is all. No threads. No libraries. No excuses. If something changes, we know exactly who to blame.
Was it that simple?
The PoC script: poc.sh
Coordinates with the kernel module: umem_poke.c
The script does not do magic address translation in bash.
Which is probably good news for everyone. It only coordinates the experiment: it starts the victim, gets the address printed by the process, and passes that VMA address to the module.
The module is the one doing the kernel-side work. It uses GUP to resolve the userspace address to the underlying page, computes the linear mapping address destination byte, and then performs the write.
After all that machinery, the corruption itself is still disappointingly simple:
*dst_target = act.value;That is it.
- No
ptrace(). - No
copy_to_user(). - No
access_ok(). - No “Dear Kernel, may I please touch userspace?”
Just a normal assignment. From the kernel’s point of view, this is simply a write to a valid pointer.
Which leads to a slightly uncomfortable realization: once a userspace page is reached through the linear mapping, it stops being special. It is just memory. And the kernel is very good at writing to memory.
“But Surely Read-Only Memory Is Safe?”
A reasonable objection is: “Fine, but this probably works only on writable pages.” That would be reassuring… Would it really?
Even then, the wall would still have a door. Unfortunately, reality is even less reassuring.
The experiment works even when the target string is moved from .bss to .rodata.
In other words, the process sees the page as read-only. The process itself cannot modify the string.
And yet, after the userspace address has been translated to its corresponding location in the linear mapping, changing the supposedly immutable data still requires nothing more sophisticated than:
*dst_target = act.value;
- No page permissions are changed.
- No special write mechanism is invoked.
- No dedicated “modify userspace memory” API is used.
Just a normal store through a valid kernel pointer.
So the surprising part is not that the kernel, in principle, has enough privilege to modify the page. The surprising part is that once the page is reached through the linear mapping, the actual modification is indistinguishable from writing to any other ordinary kernel address.
Same physical page. Different virtual permissions. Same single dereference.
The Grand Finale
Before the write, the program prints one string.
After the write, it prints a different one.
buildroot login: root
# /usr/umem_poke/poc.sh
running without corruption
message address: 0x0000000000400168
<TOKEN>
running again with corruption
[ 27.675393] umem_poke: loading out-of-tree module taints kernel.
message address: 0x0000000000400168
[ 28.751270] umem_poke: req: poke memory for pid=107 mem[400168]=1074707572726f63
[ 28.752020] umem_poke: act: poke memory for pid=107 mem[400168]=1074707572726f63
corrupt
# The process does not crash. The kernel does not panic. No alarms ring. No dramatic music starts.
The application simply continues running with modified data. Which, from a functional safety perspective, is often the most interesting outcome.
Not: “The system exploded.”
But: “The system kept working… incorrectly.”
From Layout Curiosity to Concrete Effect
At this point, the full chain becomes visible:
+---------------------------+
| shared physical memory |
+---------------------------+
|
\ /
V
+---------------------------+
| possible adjacency |
+---------------------------+
|
\ /
V
+---------------------------+
| kernel object at page end |
+---------------------------+
|
\ /
V
+---------------------------+
| kernel write defect |
+---------------------------+
|
\ /
V
+---------------------------+
| ordinary pointer store |
+---------------------------+
|
\ /
V
+---------------------------+
| userspace data corruption |
+---------------------------+
|
\ /
V
+---------------------------+
| incorrect but apparently |
| normal behavior |
+---------------------------+
So the original question: “Can kernel and user pages be physically adjacent?”
Now has a more complete answer: Yes. And if a kernel write goes in the wrong direction, the next page may belong to a perfectly innocent process. That process may continue running as if nothing happened, except for the small detail that its data is no longer what it thinks it is.
Why This Matters
From a safety perspective, the concern is not: user → kernel corruption (blocked by MMU)
The concern is:
kernel → anything else
Because in the linear mapping:
- everything shares the same physical space
- adjacency is not controlled
- allocators optimize for performance, not isolation
So when something goes wrong: the target is simply “the next page”
And what that page is… depends on the moment.
Bigger Picture
This PoC is not proving a vulnerability.
It is proving something more subtle: Linux enforces virtual access separation, but does not guarantee physical separation between kernel and userspace allocations.
And in safety: lack of guarantees is already a problem.
Final Thought
The tool didn’t find a bug and this article does not imply Linux is unsafe. It found something more annoying: an assumption that is not always true.
Meaning that physical separation is not an inherent property of the Linux memory manager and must be established through additional architectural controls if required by a safety case.